Hedged Read 简介
If a read from a block is slow, start up another parallel, ‘hedged’ read against a different block replica. We then take the result of which ever read returns first (the outstanding read is cancelled). This ‘hedged’ read feature will help rein in the outliers, the odd read that takes a long time because it hit a bad patch on the disc, etc.
This feature is off by default. To enable this feature, set dfs.client.hedged.read.threadpool.size to a positive number. The threadpool size is how many threads to dedicate to the running of these ‘hedged’, concurrent reads in your client.
Then set dfs.client.hedged.read.threshold.millis to the number of milliseconds to wait before starting up a ‘hedged’ read. For example, if you set this property to 10, then if a read has not returned within 10 milliseconds, we will start up a new read against a different block replica.
This feature emits new metrics(几个新指标参数介绍):
- hedgedReadOps – 发起 hedged read 操作的次数
- hedgeReadOpsWin – how many times the hedged read ‘beat’ the original read
- hedgedReadOpsInCurThread – how many times we went to do a hedged read but we had to run it in the current thread because
dfs.client.hedged.read.threadpool.sizewas at a maximum.
hdfs-site.xml 配置参数模版
<configuration>
<property>
<name>dfs.client.hedged.read.threadpool.size</name>
<value>128</value>
</property>
<property>
<name>dfs.client.hedged.read.threshold.millis</name>
<value>2000</value>
</property>
</configuration> 测试环境
就跑 100G 的 TPCH Parquet 测试,数据存储在 emr 的 hdfs 上面,2 副本,以此避免数据全部都短路读,不会涉及 network io。(EMR 有 3 个 worker 节点)。
StarRocks 配置:1 FE + 2 BE
通过分别调整 dfs.client.hedged.read.threadpool.size 和 dfs.client.hedged.read.threshold.millis 来对 hedged read 进行测试,
所有 SQL 会跑 5 次。第一次是预热,不算。后面 4 次取平均值。
内网 starrocks ping emr 集群,平均延迟只有 0.6 ms。
实验结果单位为毫秒。
单线程查询测试
| 关闭 hedged read-1 | 关闭 hedged read-2 | 关闭 hedged read-3 | 关闭 hedged read-4 | 128线程/5ms | 128线程/50ms | 128线程/500ms | 128线程/1000ms | 128线程/2000ms | 32线程/3000ms | 1024线程/2500ms | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| q1 | 4780 | 4923 | 4836 | 4808 | 5582 | 5363 | 5071 | 5252 | 4955 | 5182 | 5280 |
| q2 | 1033 | 1104 | 1048 | 1035 | 1160 | 1055 | 1073 | 1081 | 1067 | 1150 | 1067 |
| q3 | 3732 | 3936 | 3782 | 3670 | 4883 | 3981 | 3719 | 3727 | 3823 | 4027 | 3867 |
| q4 | 1933 | 1946 | 1931 | 1876 | 2237 | 1978 | 1959 | 1998 | 1997 | 1989 | 2039 |
| q5 | 4387 | 4335 | 4344 | 4317 | 5400 | 4756 | 4552 | 4465 | 4781 | 4348 | 4423 |
| q6 | 2058 | 1990 | 2079 | 1994 | 2624 | 2182 | 2036 | 2039 | 2053 | 2046 | 2040 |
| q7 | 4573 | 4805 | 4512 | 4551 | 5634 | 4957 | 4624 | 4649 | 4590 | 4886 | 4664 |
| q8 | 3866 | 3804 | 3829 | 3757 | 4845 | 4371 | 3836 | 3890 | 3940 | 3900 | 3880 |
| q9 | 7834 | 8068 | 7862 | 7962 | 9397 | 8360 | 7918 | 7977 | 7931 | 8101 | 8004 |
| q10 | 4378 | 4570 | 4457 | 4472 | 4910 | 4740 | 4631 | 4617 | 4602 | 4617 | 4636 |
| q11 | 692 | 706 | 696 | 720 | 809 | 704 | 715 | 706 | 724 | 741 | 716 |
| q12 | 2126 | 2213 | 2194 | 2172 | 2633 | 2209 | 2210 | 2202 | 2264 | 2375 | 2224 |
| q13 | 3675 | 3883 | 3707 | 3695 | 4346 | 3927 | 3659 | 3706 | 3755 | 3968 | 3692 |
| q14 | 2400 | 2433 | 2396 | 2433 | 3538 | 2752 | 2521 | 2514 | 2522 | 2477 | 2552 |
| q15 | 2387 | 2389 | 2386 | 2379 | 3372 | 2708 | 2480 | 2486 | 2515 | 2474 | 2474 |
| q16 | 1439 | 1562 | 1431 | 1394 | 1569 | 1416 | 1418 | 1435 | 1434 | 1510 | 1469 |
| q17 | 2285 | 2317 | 2290 | 2310 | 3070 | 2674 | 2437 | 2391 | 2361 | 2413 | 2453 |
| q18 | 7960 | 8243 | 8043 | 7999 | 8394 | 8211 | 7868 | 7868 | 7933 | 8280 | 8078 |
| q19 | 2474 | 2478 | 2499 | 2530 | 3567 | 2841 | 2639 | 2544 | 2610 | 2554 | 2584 |
| q20 | 3468 | 3481 | 3468 | 3475 | 4415 | 3738 | 3702 | 3694 | 3610 | 3710 | 3647 |
| q21 | 6565 | 6886 | 6608 | 6658 | 8484 | 7969 | 6788 | 6728 | 6847 | 7039 | 6871 |
| q22 | 1107 | 1169 | 1136 | 1134 | 1247 | 1209 | 1126 | 1136 | 1215 | 1183 | 1136 |
| 合计 | 75152 | 77241 | 75534 | 75341 | 92116 | 82101 | 76982 | 77105 | 77529 | 78970 | 77796 |
可以看出开启 hedged read 是会对性能有影响。但是开启 hedged read 后,只要参数设置的不是特别离谱,影响没那么大。
单线程查询 + 慢节点
我使得一个 HDFS 节点成为慢节点,所有请求随机延迟 0~10ms 之间。该 HDFS 节点上面没有 be 运行的。
随机延迟命令
sudo tc qdisc add dev eth0 root netem delay 5ms 5ms 25%
删除延迟
sudo tc qdisc del dev eth0 root netem
| 关闭 hedged read | 128线程/1000ms | 128线程/3000ms | |
|---|---|---|---|
| q1 | 33747 | 5589 | 13238 |
| q2 | 31971 | 6661 | 16145 |
| q3 | 34164 | 8194 | 16634 |
| q4 | 19320 | 4770 | 9585 |
| q5 | 33831 | 7152 | 13059 |
| q6 | 29244 | 4925 | 12697 |
| q7 | 39533 | 8796 | 18245 |
| q8 | 47474 | 8628 | 20814 |
| q9 | 69217 | 11396 | 25086 |
| q10 | 61744 | 10135 | 20748 |
| q11 | 22737 | 5676 | 13089 |
| q12 | 31417 | 8268 | 19600 |
| q13 | 55564 | 5961 | 12001 |
| q14 | 40934 | 5454 | 13282 |
| q15 | 38234 | 6620 | 15216 |
| q16 | 18079 | 3695 | 7752 |
| q17 | 44604 | 5260 | 10740 |
| q18 | 48506 | 14525 | 22113 |
| q19 | 38080 | 6190 | 14866 |
| q20 | 40122 | 7786 | 13278 |
| q21 | 47191 | 15348 | 28810 |
| q22 | 24983 | 4089 | 9058 |
| 合计 | 850696 | 165118 | 346056 |
其实只要一旦存在慢节点,hedged read 一定是正优化的,只是多少的问题。
三并发,BE CPU 全部打满的情况
| 关闭 hedged read | 32 线程/2000ms | 128线程/1000ms | 128线程/2000ms | |
|---|---|---|---|---|
| q1 | 14129 | 14499 | 14546 | 14553 |
| q2 | 1275 | 1383 | 1380 | 1332 |
| q3 | 9158 | 9553 | 9638 | 9439 |
| q4 | 5112 | 4941 | 5300 | 5057 |
| q5 | 11681 | 11899 | 11748 | 11658 |
| q6 | 5836 | 6005 | 5993 | 5948 |
| q7 | 12007 | 12399 | 12349 | 12308 |
| q8 | 10794 | 11202 | 11216 | 10464 |
| q9 | 19911 | 19814 | 19269 | 19397 |
| q10 | 10424 | 10512 | 10655 | 10591 |
| q11 | 1427 | 1512 | 1522 | 1496 |
| q12 | 5136 | 5048 | 5301 | 4946 |
| q13 | 9357 | 9642 | 9629 | 9550 |
| q14 | 6485 | 6870 | 6779 | 6863 |
| q15 | 6762 | 7017 | 7100 | 7064 |
| q16 | 3369 | 2776 | 2707 | 2447 |
| q17 | 6028 | 6367 | 6518 | 6466 |
| q18 | 23411 | 23409 | 23325 | 24066 |
| q19 | 7312 | 7516 | 7611 | 7537 |
| q20 | 7127 | 7476 | 7827 | 7685 |
| q21 | 18357 | 19285 | 19629 | 19313 |
| q22 | 1952 | 1940 | 1970 | 2007 |
| 合计 | 197050 | 201065 | 202012 | 200187 |
从结果上看起来貌似查询并发和 hedged read 之间并没有太大的影响。
总结
线程池的影响
Hedged read 是和 DFSClient 绑定在一起,说明一个 Hdfs client 会有一个 hedged read 线程池。然后那个线程池是 ThreadPoolExecutor。
Hadoop FileSystem 里面会自带一个 cache,他的 cache key 是:
static class Key {
final String scheme;
final String authority;
final UserGroupInformation ugi;
final long unique; // an artificial way to make a key unique
Key(URI uri, Configuration conf) throws IOException {
this(uri, conf, 0);
}
Key(URI uri, Configuration conf, long unique) throws IOException {
scheme = uri.getScheme()==null ?
"" : StringUtils.toLowerCase(uri.getScheme());
authority = uri.getAuthority()==null ?
"" : StringUtils.toLowerCase(uri.getAuthority());
this.unique = unique;
this.ugi = UserGroupInformation.getCurrentUser();
}
@Override
public int hashCode() {
return (scheme + authority).hashCode() + ugi.hashCode() + (int)unique;
}
static boolean isEqual(Object a, Object b) {
return a == b || (a != null && a.equals(b));
}
@Override
public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (obj instanceof Key) {
Key that = (Key)obj;
return isEqual(this.scheme, that.scheme)
&& isEqual(this.authority, that.authority)
&& isEqual(this.ugi, that.ugi)
&& (this.unique == that.unique);
}
return false;
}
@Override
public String toString() {
return "("+ugi.toString() + ")@" + scheme + "://" + authority;
}
}
}可以看出来,这个 CacheKey 主要是根据 schema 和 authority 进行计算。这意味着在一个 BE 中,所有针对同一个 HDFS 集群的请求,都是用的同一个 DFSClient,也就是用着同一个 hedged read 线程池。

从注释上可以看出,这个线程池是动态扩缩容的,不会存在占着茅坑不拉屎。
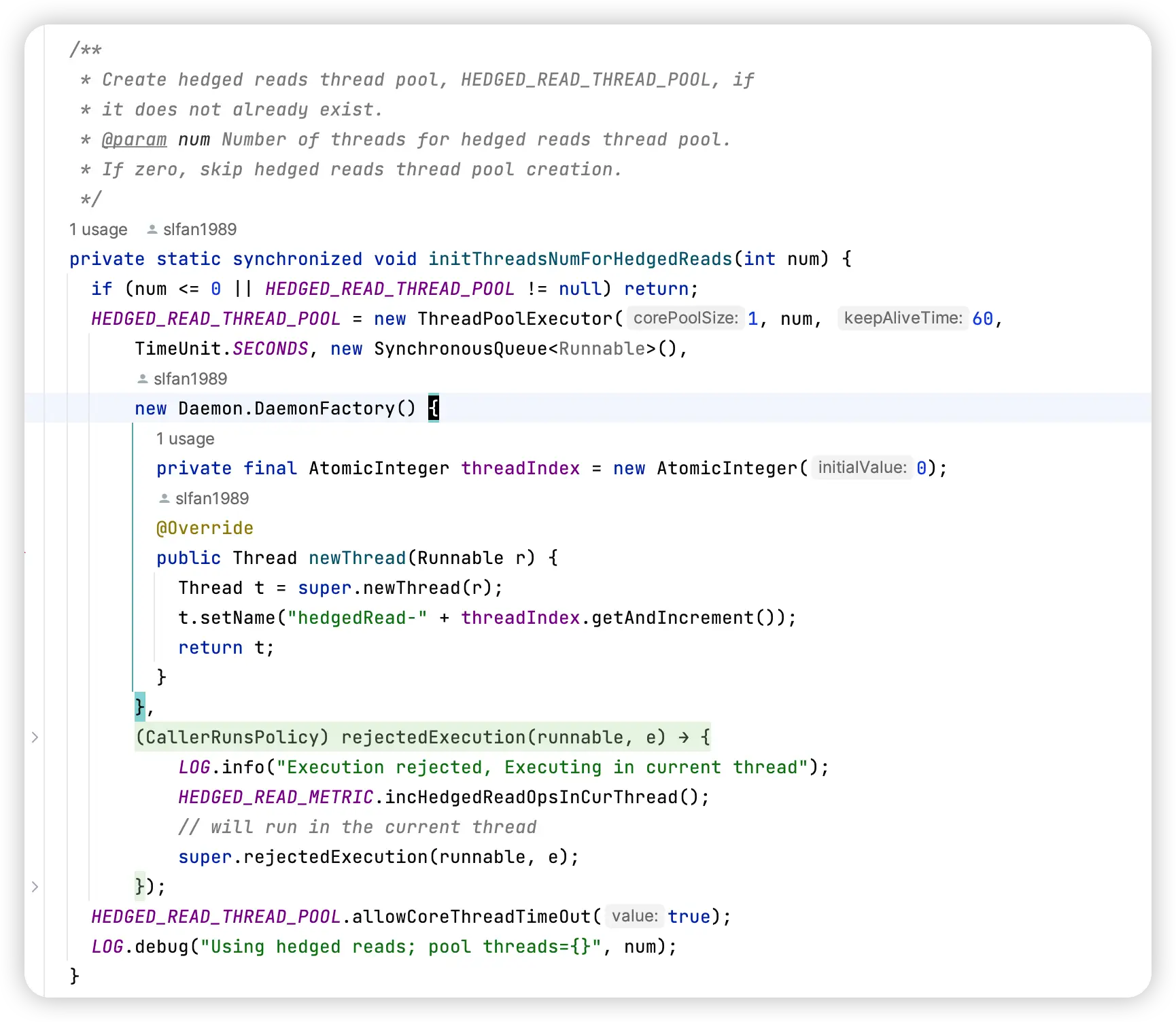
创建 hedged read 线程池时候,这个 num 是我们配置的线程池大小,可以看出当线程 idle 超过 60s 后,就会被终止。
我自己也用 jstack 确认过,当没有 query 时,jstack 是打不出 hedged read 的线程。
推荐值
这里推荐给 dfs.client.hedged.read.threshold.millis 设置一个较大的值,比如 3000ms,这样能够有效避免极端情况。然后如果用户的 HDFS 正常的话,也不会发起 hedged read,使得数据多读。
关于 dfs.client.hedged.read.threadpool.size 的大小,实验上看不出 32/128 之间的影响,故这里推荐 128。
[…] Hedged Read 引入 StarRocks 的效果,见 StarRocks 中关于 Hadoop Hedged Read 性能测试 这篇文章。当时得出来的结论是在存在慢节点的情况下,hedged read […]
学到了