这段时间,一位用户间断性的吐槽 StarRocks 有些 SQL 比 Trino、Apache Doris 慢了 n 个数量。起初我们没有太在意,觉得可能是某些 bad case 引起。后面感谢用户的定位,发现了这些查询的数据源大多为 Hive Text 格式(也就是 CSV 格式)。
天将降大任于斯人也,领导便把这个重任交付与我。其实问题一到手,我是非常疑惑的,这个 CSV Reader 在我入职前就有了,按道理也是被广泛使用,怎么还会有性能问题?而且一个行存的格式,能有啥特别的优化手段,不会是 BUG 把?
不过既然用户说比 Doris、Trino 慢了很多,那就搭一个测试环境呗。
初步测试
我选择了一台 4 core,32GB 内存的老爷机作为测试环境。分别安装上了 Apache Doris 2.0,StarRocks 3.1.2, Trino 424。然后我还额外加了一位重磅选手 ClickHouse(23.8.1.2785),大家同台竞技一把。
第一步当然就是造数据,我在 Hive 上面创建一张带分区的 text 格式表,这张表包含各种类型,有 BIGINT,有 STRING,还有 ARRAY<STRING> 等等。插入一行数据后,反复执行 INSERT INTO tbl SELECT * FROM tbl 来对表进行膨胀,最后搞了差不多有 5.1 G 的大小,够我们的老爷机 CPU 打满分析一会了。
SQL 语句我也不玩虚的,就来 3 条 SQL:
- 全表扫:
SELECT * FROM table ORDER BY 1 LIMIT 1。 - 扫一行,看结果会不会立刻返回:
SELECT * FROM table LIMIT 1。 COUNT(*),看有没有做少读列:SELECT COUNT(*) FROM table。
大家都跑 3 轮,我只取第 3 次结果。
Apache Doris
MySQL [(none)]> select * from csv_benchmark_hdfs order by 1 limit 1;
1 row in set (43.973 sec)
MySQL [(none)]> select * from csv_benchmark_hdfs limit 1;
1 row in set (0.323 sec)
MySQL [(none)]> select count(*) from csv_benchmark_hdfs;
1 row in set (43.866 sec)ClickHouse
SELECT * FROM csv_benchmark_hdfs ORDER BY 1 ASC LIMIT 1
1 row in set. Elapsed: 42.858 sec.
SELECT * FROM csv_benchmark_hdfs LIMIT 1
1 row in set. Elapsed: 0.027 sec.
SELECT count(*) FROM csv_benchmark_hdfs;
1 row in set. Elapsed: 42.830 sec.有一说一 ClickHouse 真省内存,CPU 利用率还低。
Trino
Trino 太慢了,不想测 3 轮了,随便选一轮吧。
select * from csv_benchmark_hdfs order by 1 limit 1;
4:24 [11M rows, 5.09GB] [41.5K rows/s, 19.7MB/s]
select * from csv_benchmark_hdfs limit 1;
7.46 [9.61K rows, 4.58MB] [1.29K rows/s, 628KB/s]
select count(*) from csv_benchmark_hdfs;
4:24 [11M rows, 5.09GB] [41.5K rows/s, 19.7MB/s]StarRocks
select * from csv_benchmark_hdfs order by 1 limit 1;
1 row in set (1 min 47.561 sec)
select * from csv_benchmark_hdfs limit 1;
1 row in set (0.369 sec)
select count(*) from csv_benchmark_hdfs;
1 row in set (48.348 sec)排除掉 Trino 不考虑,StarRocks 在 CSV 全表扫的场景下,那性能是相当的差,比 ClickHouse 和 Doris 慢了不是一个数量级。不过这也说明我们有很大的优化空间,那么该如何优化呢?
初步优化
遇事不决,直接火焰图。
这个图是拿 OSS 测的时候捕获的,AWS 的栈可以忽略不计。

我们主要看 parse_csv 这个方法,可以看到里面有 __dynamic_cast,std::__detail::_Map_base, std::ctype<char>::do_tolower 和 std::use_facet<std::ctype<char>> 这些看起来和解析 CSV 无关的代码,而且占了很大的比重。而且离谱的是,__dynamic_cast 和 std::use_facet<std::ctype<char>> 在代码里面压根就不存在。
没办法,对于不存在的方法,那只能祭出 GDB,在 __dynamic_cast 上面打个断点:
(gdb) bt
#0 __cxxabiv1::__dynamic_cast (src_ptr=0xac26120 <(anonymous namespace)::ctype_c>, src_type=0x9e28f30 <typeinfo for std::locale::facet>, dst_type=0x9e2a3f8 <typeinfo for std::ctype<char>>,
src2dst=src2dst@entry=0) at ../../.././libstdc++-v3/libsupc++/dyncast.cc:50
#1 0x00000000082f7b0b in std::use_facet<std::ctype<char> > (__loc=...) at /workspace/gcc/x86_64-pc-linux-gnu/libstdc++-v3/include/bits/locale_classes.tcc:139
#2 0x0000000005316bb9 in std::tolower<char> (__loc=..., __c=114 'r') at /opt/gcc/usr/include/c++/10.3.0/bits/locale_facets.h:2650
#3 boost::algorithm::detail::to_lowerF<char>::operator() (this=<synthetic pointer>, this=<synthetic pointer>, Ch=114 'r')
at /var/local/thirdparty/installed/include/boost/algorithm/string/detail/case_conv.hpp:49
#4 boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default>::dereference (this=<synthetic pointer>) at /var/local/thirdparty/installed/include/boost/iterator/transform_iterator.hpp:130
#5 boost::iterators::iterator_core_access::dereference<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default> > (f=<synthetic pointer>...) at /var/local/thirdparty/installed/include/boost/iterator/iterator_facade.hpp:550
#6 boost::iterators::detail::iterator_facade_base<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default>, char, boost::iterators::random_access_traversal_tag, char, long, false, false>::operator* (this=<synthetic pointer>)
at /var/local/thirdparty/installed/include/boost/iterator/iterator_facade.hpp:656
#7 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_construct<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default> > (this=0x7ffe9d810b00, __beg=..., __end=..., __end=...)
at /opt/gcc/usr/include/c++/10.3.0/bits/basic_string.tcc:172
#8 0x00000000053191b8 in std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_construct_aux<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default> > (__end=..., __beg=...,
this=0x7ffe9d810b00) at /opt/gcc/usr/include/c++/10.3.0/bits/basic_string.h:247
#9 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_construct<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default> > (__end=..., __beg=..., this=0x7ffe9d810b00)
at /opt/gcc/usr/include/c++/10.3.0/bits/basic_string.h:266
#10 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::basic_string<boost::iterators::transform_iterator<boost::algorithm::detail::to_lowerF<char>, __gnu_cxx::__normal_iterator<char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, boost::use_default, boost::use_default>, void> (__a=..., __end=..., __beg=..., this=0x7ffe9d810b00)
at /opt/gcc/usr/include/c++/10.3.0/bits/basic_string.h:628
#11 boost::algorithm::detail::transform_range_copy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, boost::algorithm::detail::to_lowerF<char> > (Functor=..., Input=...) at /var/local/thirdparty/installed/include/boost/algorithm/string/detail/case_conv.hpp:122
#12 boost::algorithm::to_lower_copy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > (Loc=..., Input=...)
at /var/local/thirdparty/installed/include/boost/algorithm/string/case_conv.hpp:79
#13 starrocks::HdfsTextScanner::parse_csv (this=0x7ffc29af2000, chunk_size=4096, chunk=0x7ffe9d810e10) at /root/starrocks/be/src/exec/hdfs_scanner_text.cpp:284好家伙,原来都是小写转换里面来的,你可以注意到 std::use_facet 也在栈里面。所以罪魁祸首就是 boost::to_lower_copy() 这个方法。
好了,原因大概理清楚了,那我们看看咋改。
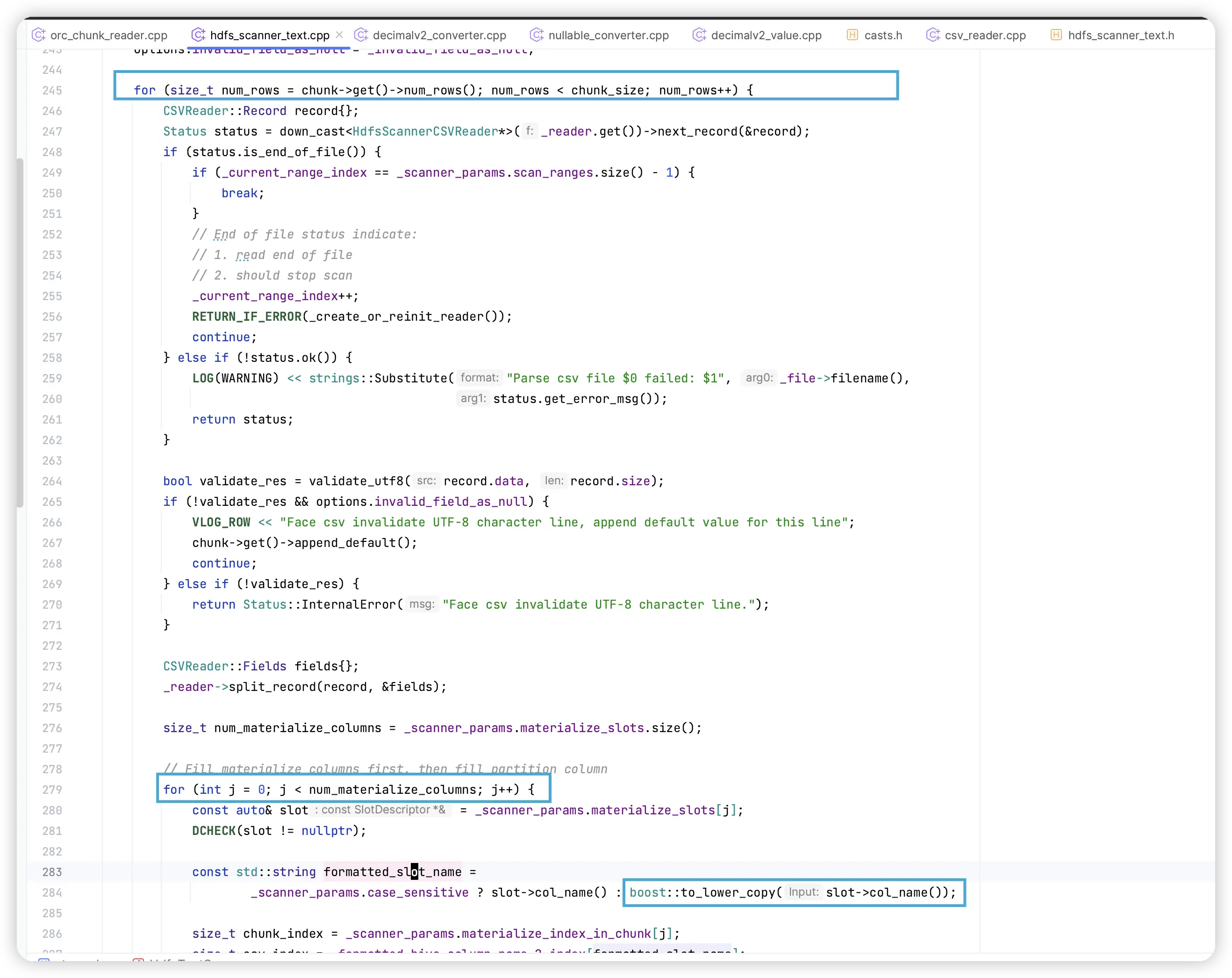
外层的 for 循环是处理每一行文本,里面一个 for 循环是处理一行的每一列数据。然后这个 boost::to_lower_copy() 方法每一行的每一列都要执行一次。其实它 format 的都是列名,我寻思每一行的列名也不会变吧,何必每行每列都要执行一遍。
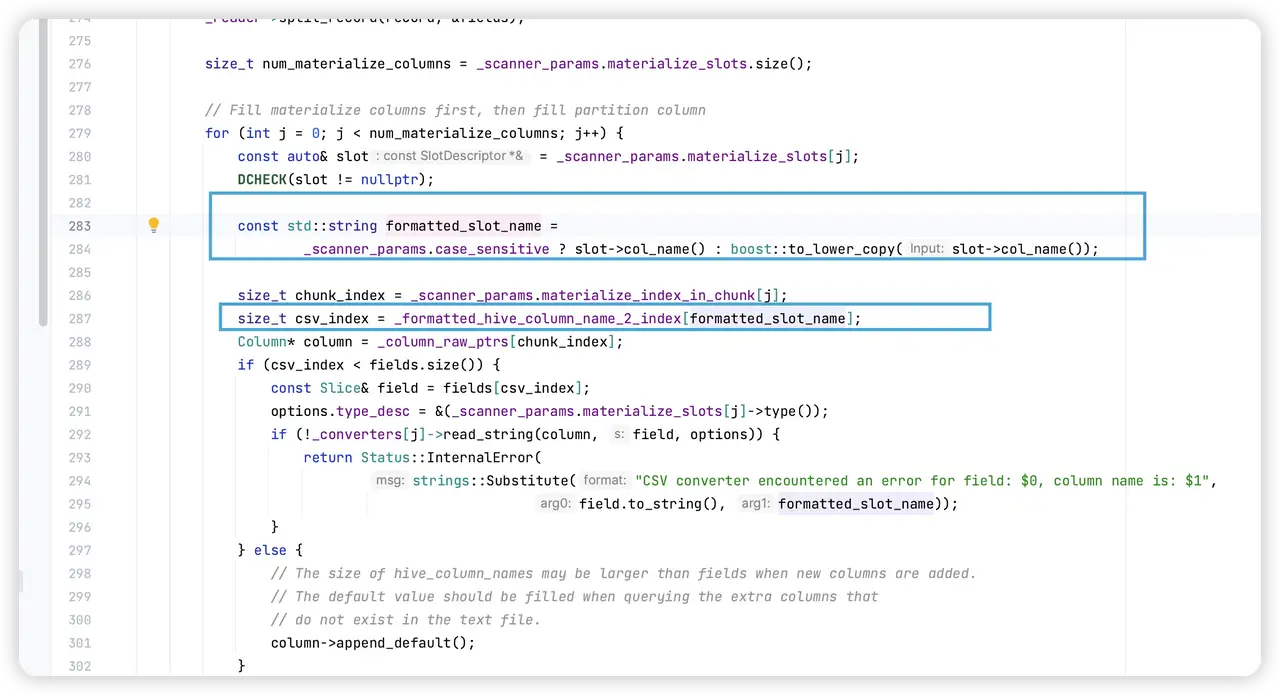
前面之所以要 format 列名,就是为了从一个 map 里面找到该列对应的 csv_index,即这一列对应的是 csv 文件中中的哪一列。虽然 map 的 get() 是一个 $O(1)$ 的操作,但是为了一个简单的列映射,每一行每一列都要执行一次,那这代价也太大了吧。
不过解决办法也很简单,我在开始初始化 CSVReader 前,就先把这个映射建立好。然后不用 map,而是用 vector,结构差不多就是 vector<int> 这样,下标表示 table 的列顺序,值表示在 csv 文件中的第几列,这样就比 map 轻量多了。然后也能省去频繁执行 boost::to_lower_copy() 的开销。
代码往后拉发现添加分区列的操作也很迷,每扫一行,添加一行分区列。
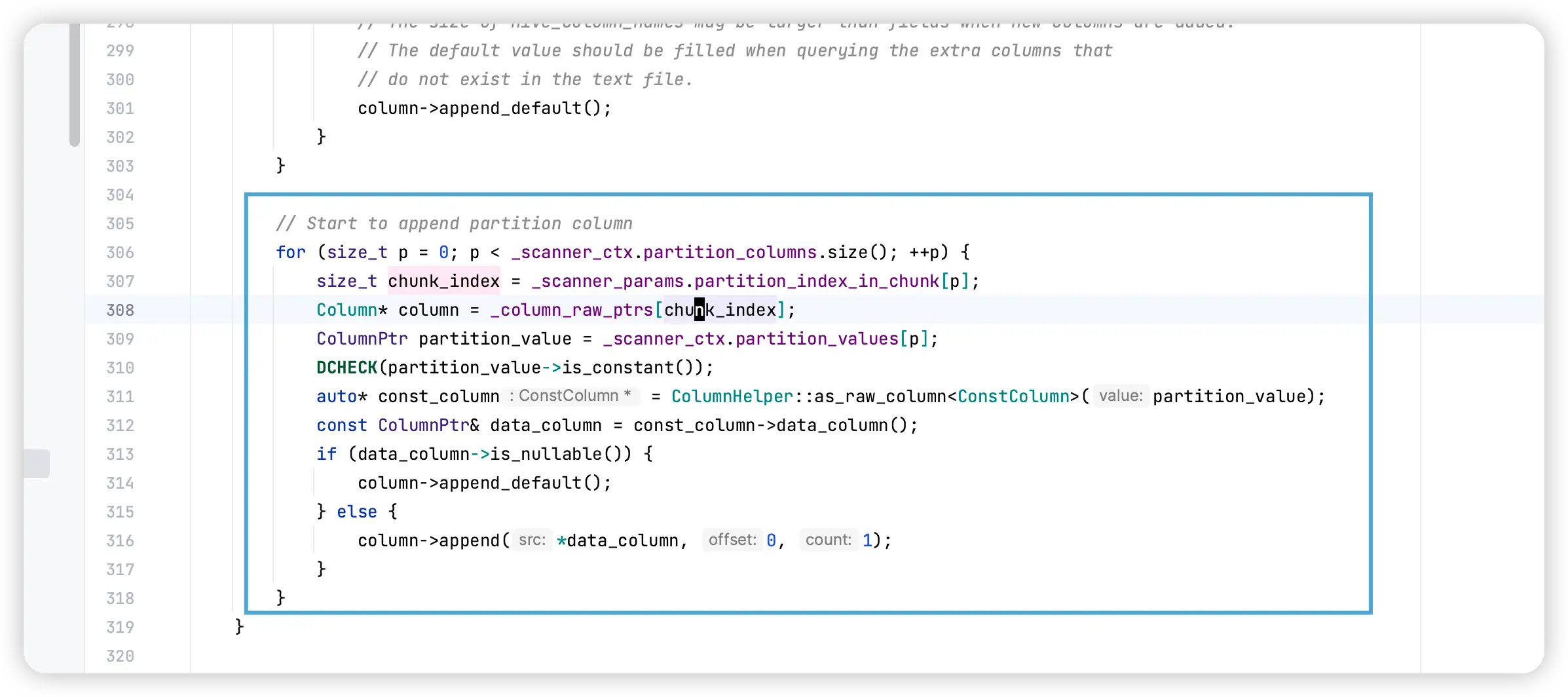
我完全可以 csv 读完后,一次性 append n 行分区列,这样还可以触发 SIMD,肯定比一次添加一行更加高效。
经过修改,我提了一个 PR:https://github.com/StarRocks/starrocks/pull/30028,合入后,再测一把性能吧。
select * from csv_benchmark_hdfs order by 1 limit 1;
1 row in set (49.455 sec)
select * from csv_benchmark_hdfs limit 1;
1 row in set (0.122 sec)
select count(*) from csv_benchmark_hdfs;
1 row in set (48.348 sec)乖乖,就这么一改,性能直接翻了一番?
进一步优化
现在成绩看起来和 Doris、ClickHouse 差不多了,但是显然还有进一步优化的空间,遂再一次采集火焰图。
老样子,忽略 AWS 的堆栈。

可以看到 CSVReader::split_record 还是有点慢,而且整个 parse_csv 堆栈中,有好多的 new,free 的操作,这说明我们还有频繁的申请对象。

可以看见我们每一行都会创建一个 fields 数组(其就是一个 vector<Slice> 的结构),然后把一行 csv 按分隔符切分成多个 field,emplace_back() 到 fields 里面。可想而知,这里会频繁的遇到 vector 的扩容。
那我为什么不能每一行共用一份 fields 呢?那就不用操心数组每一行都要扩容一次。
然后再看这一行方法,read_string,就是把 csv 的字符串根据表的类型,进行类型转换。
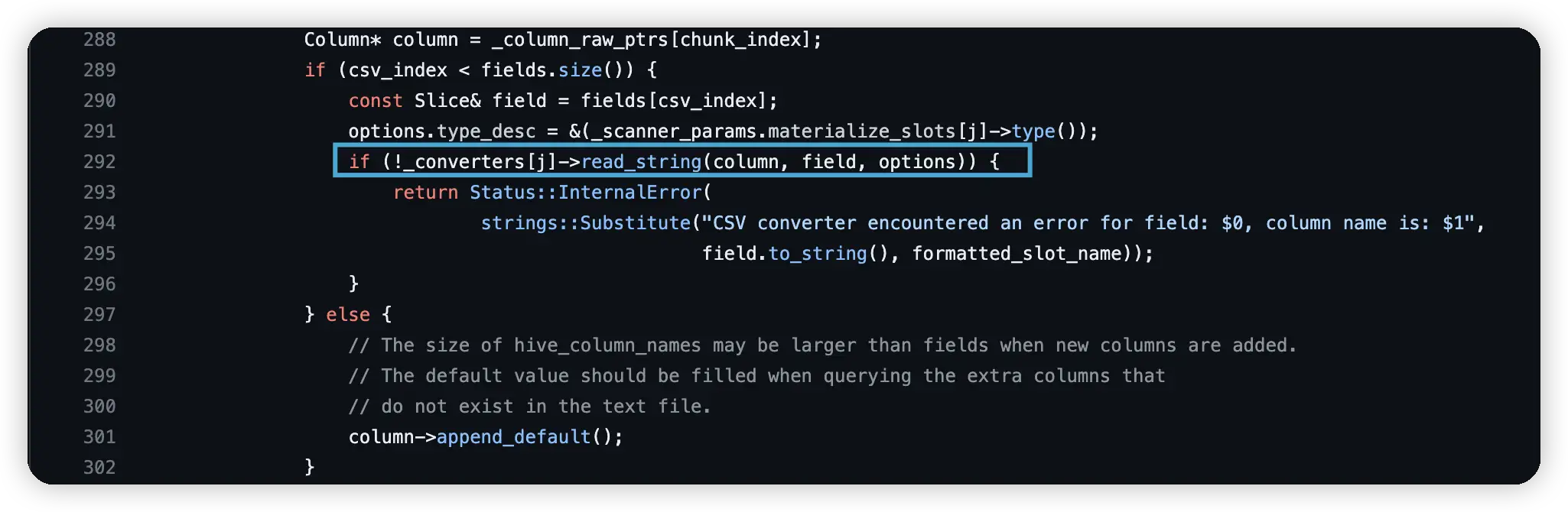

然后你可以注意到,这个 read_string() 每一次都会拷贝一次 Slice 对象,我的乖乖,想想每一行的每一列都要拷贝,这个开销还是很大的,而且这是完全不必要的拷贝,引用不就完事了?
所以我又提了一个 pr:https://github.com/StarRocks/starrocks/pull/30137,合入后,再一次测试性能。
select * from csv_benchmark_hdfs order by 1 limit 1;
1 row in set (47.252 sec)
select * from csv_benchmark_hdfs limit 1;
1 row in set (0.110 sec)
select count(*) from csv_benchmark_hdfs;
1 row in set (48.348 sec)快了 2s,但是还是和 Doris 和 ClickHouse 有差距,咋回事呢?
试试 OSS 存储看看,因为 StarRocks 的 HDFS 是走 JNI 的,可能性能不如 C++ 写的 LIBHDFS3。而 OSS 大家都是走 S3 SDK,均是 C++ 写的。
因为 ClickHouse 的 Hive 不支持 OSS,跑不出来,所以就只能跑个 Doris 和 StarRocks 的。
Doris
select * from csv_benchmark order by 1 limit 1;
1 row in set (50.640 sec)
select * from csv_benchmark limit 1;
1 row in set (0.613 sec)
select count(*) from csv_benchmark;
1 row in set (45.242 sec)Doris 走了 OSS 后,反而比 HDFS 更慢了,不晓得为啥,感觉有点不合常理。
StarRocks
select * from csv_benchmark order by 1 limit 1;
1 row in set (46.606 sec)
select * from csv_benchmark limit 1;
1 row in set (0.328 sec)
select count(*) from csv_benchmark_hdfs;
1 row in set (46.509 sec)好吧,好像没啥参考意义,就只是在 HDFS 的基础上再快了 1s。
后续
因为 HDFS 大伙的实现不同,所以后面自己测了下 ClickHouse 和 StarRocks 开启 Cache 的场景,在排除了外部存储系统的干扰后,大家的查询时间几乎一致。这至少说明了在 csv 解析这块,我们已经做得差不多了,没有太大的优化空间了,也许后续应该好好的优化下 HDFS 的访问。
三家在查询性能相似的情况下,大家的峰值内存占用分别如下:670MB(ClickHouse) => 900MB(StarRocks) => 1.2G(Doris)
总结
在这一次 CSV 的优化上,第一次让我感受到了细微的代码优化,有时候能带来成倍的性能提升,毕竟两个 PR 加起来的代码也就 100 来行。
ClickHouse 还是全方位牛逼,就是湖的易用性几乎为 0,连 catalog 都没有,然后 Hive 表必须要有分区列,等等,一言难尽。
ClickHouse 的 limit 1 返回的真的很快,估计和实现有关。可能 ClickHouse 把 limit 1 下推到了 csv 解析这块,真就扫了一行。而 StarRocks 是至少也会扫描一个 chunk 4096 行,然后再取 1 行,就自然慢了。
up又有绩效了
只能说对绩效没啥卵用,😨
佬越来越强了😀
数据库的 CRUD boy 罢了
学习了
点赞,学习了。