在千篇一律 arrow-cpp 系的 Parquet Reader 实现中,arrow-rs 上面的实现着实让人眼前一亮,这里简单记录下。
Parquet C++ Reader 早期由 Impala 团队开发,即
parquet-cpp,后合并到arrow-cpp中。Doris 引擎在早期开发的时候,借鉴了 Impala。StarRocks 又是基于 Doris fork 而来。所以这些引擎的 Parquet Reader 实现多少是有点相似的。
Bytes
arrow-rs 使用 Bytes 库存储从网络读取的连续二进制数据。
Bytes 文档:https://docs.rs/bytes/latest/bytes/
Bytes 可以简单地认为是一个 Vec<Byte> ,但是它有一个优秀的特性:零拷贝切片(slice)。
下面这个例子中,hello_part 和 world_part 都是一个指向 data 的引用,没有额外的内存拷贝。
fn main() {
let data = Bytes::from("hello world");
let hello_part = data.slice(..5);
let world_part = data.slice(6..);
println!("{:?}, {:?}", hello_part, world_part);
}Bytes 自行管理内存的释放,它有一个计数器,记录引用的切片数量,当引用数清零,内存自动释放。
上面这个例子中当 data 、hello_part 和 world_part 变量的生命周期结束,hello world 这块内存就会释放。
该特性在 IO 合并里面大有用处,IO 合并会把若干个 Parquet Page(PG) 的 IO 请求合并在一个大 IO 里面,此时从网络得到的一定是一块连续的大 buffer。
+-------+-------+-------+
| PG1 | PG2 | PG3 |
+-------+-------+-------+
↓
+-------+-------+-------+
| BUFFER |
+-------+-------+-------+ 大多数 AP 有下面两个做法:
- 把大 buffer 里面的数据,分别 MEMCPY 到 PG1、PG2 和 PG3 自己的内存上面,然后释放大 buffer(存在 MEMCPY 开销)。
- PG1、PG2 和 PG3 直接引用 buffer 上面的内存,但是因为它们的引用没有智能指针这种机制,需要确保 PG1、PG2 和 PG3 访问的时候,这个 buffer 还存在,这需要复杂的内存生命周期管理。所以它们大多直接选择了偷懒,把所有 buffer 的释放时机统一延迟到 RowGroup 结束。也就是说在最极端的
SELECT *场景下,内存里面会持有整个 RowGroup 的内存。
文件系统 API
不像其他文件系统 API 里面又是 Read() 、ReadAt() 、 Seek()、Tell() 啥的,arrow-rs 里面抽象的很干净,就两个接口:
pub struct Range {
/// The lower bound of the range (inclusive).
pub start: i64,
/// The upper bound of the range (exclusive).
pub end: i64,
}
pub trait AsyncFileReader {
/// Retrieve the bytes in `range`
fn get_bytes(&mut self, range: Range<u64>) -> BoxFuture<'_, Result<Bytes>>;
/// Retrieve multiple byte ranges.
fn get_byte_ranges(&mut self, ranges: Vec<Range<u64>>) -> BoxFuture<'_, Result<Vec<Bytes>>>;
}get_bytes() 和 get_byte_ranges() 两个接口都是异步接口,返回的是一个 future,相当于 IO 操作均为异步执行。
AsyncFileReader 是一个 interface,其可以有多个派生实现,比如 InMemory、S3、HDFS 等等。
让人眼前一亮的是 get_byte_ranges 的接口,其支持一次性访问多个 Range,类似于 Hadoop 的 Vector IO,相当于把 IO 合并的策略交给了底层的 Storage 实现。
get_byte_ranges 接口的语义是你发起几个 Range 的请求,它就返回几个 Range 对应的 Bytes(无论底下是否合并)。显然当底下的 Storage 发生了 IO 合并,get_byte_ranges 返回的是若干个指向同一个 buffer 的 slice。
这么做是合理的,毕竟不同的存储介质就应该有不同的 IO 合并策略。比如 InMemory 的数据,就没有 IO 合并的必要了。
然而现在绝大多数 AP 系统的 IO 合并都是在 Parquet/ORC reader 这一侧做的,它们能做的就是无视存储介质,无脑合并。
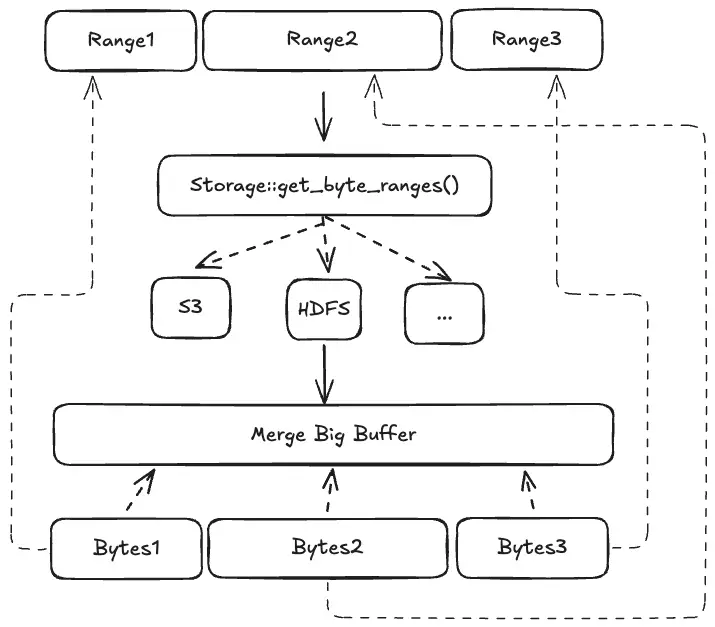
上图以 Parquet Page 的 IO 合并为例,假如有三个 Page 对应上面的三个 Range。调用 get_byte_ranges() 返回三个 Bytes,分别对应每一个 Page。不过好消息是它们引用的是同一块 IO 合并后的 buffer,没有额外的内存拷贝。
当上层的 PageReader 每消费掉一个 Page 后,buffer 上面的引用计数减一,三个 Page 消费完毕后,整个 buffer 也就会被自动释放。这避免了非得要等到 RowGroup 结束才释放 buffer 的尴尬,而且代码实现上也清晰易懂。
参考:Java 的 Hadoop Vector IO:https://medium.com/engineering-cloudera/hadoop-vectored-io-your-data-just-got-faster-50d2eef885d7
FileMetadata(Footer) 解析优化
Parquet FileMetadata 解析慢是一个头疼的问题,尤其是当列特别多的时候。不少 AP 在这方面动起了脑筋,无非就是把 FileMetadata 反序列化后的类直接拿个智能指针 hold 在内存里面,这样下次读取的时候,可以避免 thrift 的反序列化。
但是这个办法治标不治本,不过也能理解,毕竟大家反序列化的代码都是 thrift --gen 自动生成的,也不好改。
arrow-rs 反其道而行之,自己重新写了 thrift 的反序列化逻辑,性能相比于原生提升了 3.3x,如果不解析列统计信息和 page-index,性能则快了 9x。
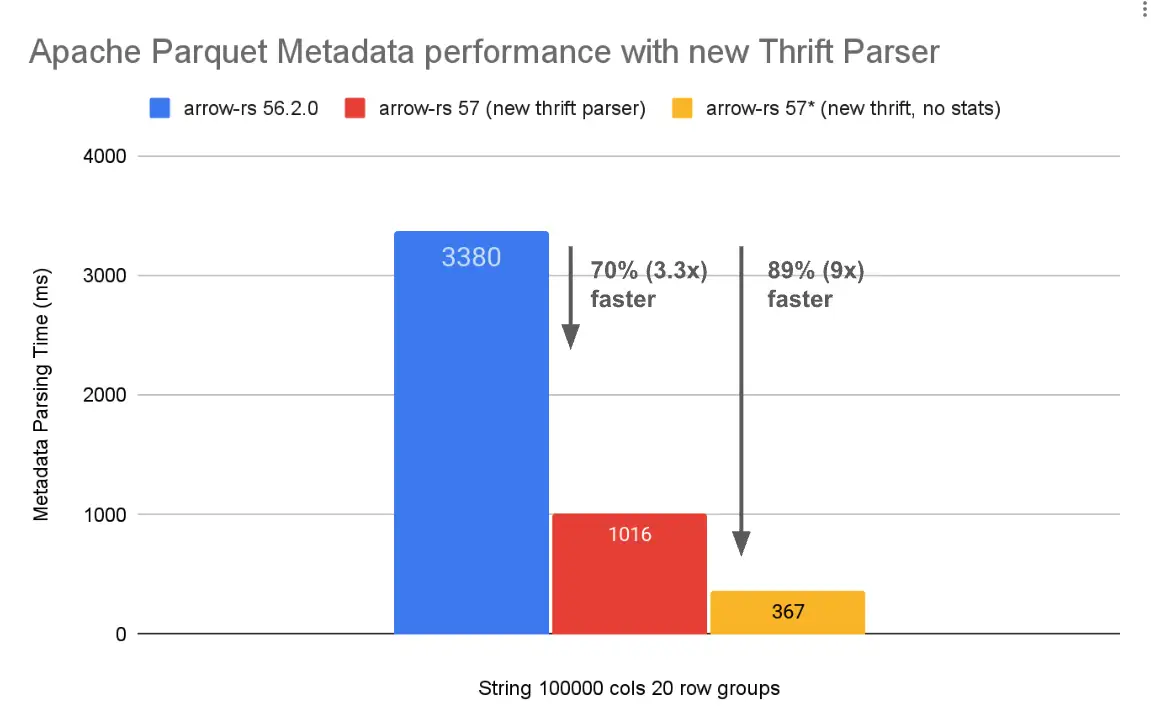
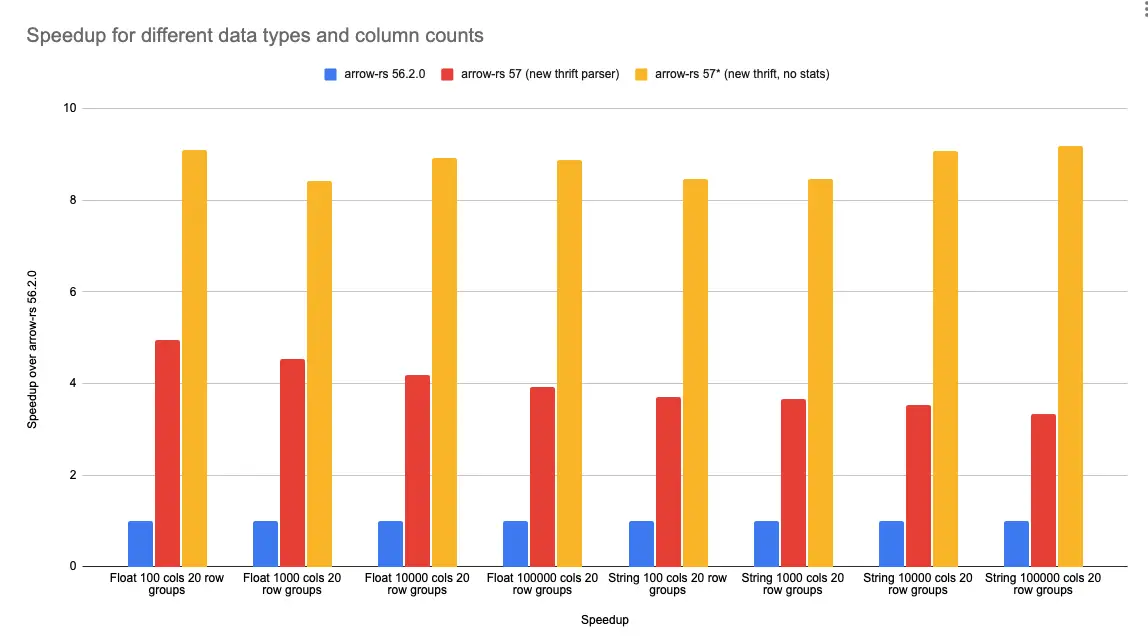
arrow-rs 56.2.0用的是 thrift-gen 自己生成的代码。- no stats 的意思是不解析 ColumnChunk 的统计信息,同时 page-index 也不解析。
这里简单列下做的优化点:
- 消除中间结果转换:
- 之前 Thrift 二进制数据 → 中间结构(FileMetadata)→ 最终 API 调用对象(ParquetMetadata)。
- 现在直接将 Thrift 二进制数据 → 最终 API 对象(ParquetMetadata)
- 优化内存分配,就是代码更加优雅点,避免小内存频繁分配。
- 对 RowGroupMetaData 和 ColumnChunkMetaData 等性能关键点进行了仔细的手工优化。
将来计划优化点:
- 只解析需要的列和需要的统计信息,比如一个列上面没有作用谓词,那么它的统计信息也不用解了(感觉这个搞了,性能又会更上一层楼)。
具体自己看博客吧:
https://arrow.apache.org/blog/2025/10/23/rust-parquet-metadata
https://github.com/alamb/parquet_footer_parsing
解耦 CPU 和 IO
传统 Parquet Reader 的实现都是 IO 和 CPU 交织在一起(假设不开启 IO 合并、prefetch 这类功能)。你可以认为是 pull 模型,即上层需要数据的时候,调用 next_batch(),驱动着 Reader 下载数据,Decode 数据。
Caller --> next_batch() --> Parquet reader
| (decides when/what to read)
v
IO request for page
v
Decode page
v
IO request for next page
v
Decode page
v
...
v
Decode + return batcharrow-rs 实现了 Parquet Decoder。你可以认为它只是一个方法类,里面不涉及任何 IO 操作。整个 Decoder 是一个 push 模型,即你把从网络拉取的二进制数据 push 给 Decoder,Decoder 会返回解码后的数据。
Caller Decoder
| try_decode() |
|------------------>|
| NeedsData(r) |
|<------------------|
| fetch ranges r |
| push_ranges(r, b) |
|------------------>|
| Data(batch) |
|<------------------|- 上层调用方调用
Decoder::try_decode(),此时 Decoder 里面没有二进制数据,就返回NeedsData(r),告诉上层我需要哪些Vec<Range>的数据。 - 上层调用方根据返回的
Vec<Range>从远端拉取数据并 push 给 Decoder。 - Decoder 解析数据,返回 Decode 后的
RecordBatch。
改成 push-based 后相比于 pull-based 的优点主要有(由 AI 总结):
更容易实现智能预取(Smart Prefetching)
- Pull 模式问题:外部代码无法预先知道下一次需要什么数据,只有当 decoder 需要数据时才会发起请求,此时解码已经阻塞。
- Push 模式优势:可以在 Decoder 上添加个
peek_next_requests()API,在处理当前 batch 时就提前知道下一个行组需要的数据范围,提前发起预取请求。同时 IO 和计算分离了,可以更容易实现一些复杂的 prefetch 策略。
优化远程存储(S3/HDFS)性能
- Pull 模式问题:必须串行读取多个小请求,在高延迟的远程对象存储场景下性能很差,或者被迫将整个文件缓存到内存/本地 SSD。当然很多系统选择在 IO 之上再加一层,处理 IO 合并来绕过该问题。
- Push 模式优势:更容易合并 IO 请求,从 Decoder 拿到的是
Vec<Range>,可以自行处理合并逻辑。
降低测试复杂度
这个主要是针对 rust 来说的,之前 arrow-rs 的 pull 模式因为 Decode 和 IO 是耦合在一起,然后因为 IO 的 API 有同步异步之分,这导致 arrow-rs 需要专门为同步/异步 IO 写两套 reader,代码有冗余。
改成 push 模式后,IO 和 Decoder 分离了。相当于 IO 的同步/异步不会影响 Decoder 的实现。现在 Decoder 都是同步的代码。
分离调度、IO 管理和解码
- Pull 模式问题:IO 操作和 CPU 解码耦合在一起,难以独立优化
- Push 模式优势:可以实现三层架构(参考 Lance 的经验):
- 调度器(Scheduler):根据元数据计算需要的 IO 范围。
- IO 管理器(IO Manager):处理 IO 请求、合并范围。可使用 IO 独立线程池。
- 解码器(Decoder):纯粹的 CPU 解码操作。可使用 CPU 独立线程池。
更灵活的内存管理
- Pull 模式问题:内存使用控制有限。
- Push 模式优势:由于 IO 调度与解码分离,可以更精确地控制何时获取数据、缓存多少数据,未来可以实现更细粒度的内存限流(throttling)。
更好的可观测性
- Pull 模式问题:只能从外部观察 reader 耗时,无法分离网络和 decode 时间(比如统计 column 的加载时间,往往会把 IO 的时间也算到里面去了)。
- Push 模式优势:IO、Decode 分离后,可以更容易地添加细粒度的性能指标(比如 Decode 可以统计存粹的 CPU 上面的开销)。
核心思想对比:
Pull 模式:decoder::next() → 内部决定是否需要 IO → 同步/异步获取数据 → 解码返回。
Push 模式:decoder::try_decode() → 返回 NeedsData(ranges) → 外部自由获取数据 → decoder::push_data(ranges) → 再次调用 try_decode() 返回 Data(batch) 或 Finished 。
这种设计让 控制权从 Decoder 转移到调用方,使得高级 IO 优化策略成为可能。
更多细节自行参考:https://github.com/apache/arrow-site/pull/741
延迟物化
延迟物化是一个重要特性,arrow-cpp 上面是没有这个功能的,反而 arrow-rs 上做了。
列 Skip
延迟物化会涉及大量的 Column->Skip() 操作,arrow-rs 在存在 page-index 的情况下,如果 Skip 行数能够直接略过整个 Page,则直接在 IO 层面上略过整个 Page。
自适应 RowSelection 策略(Bitmask vs RLE)
根据谓词过滤后的稀疏度,自适应的选择是 RLE 还是 Bitmask 的 filter。
RLE:RLE 里面存的是一堆 Skip(50) (跳 50 行),Read(50) (读 50 行)的指令。适合大范围过滤(每 10000 行选 1 行),Skip() 会直接调用 Column->Skip() 。
Bitmask:一个简单的 bitmap,标记哪一行被过滤。适合高密度过滤(读一行跳一行),arrow-rs 会把一批数据都读上来后,和 bitmap evaluate 过滤。
列缓存
这个纯粹是 arrow-rs 比较挫的地方。其原本的实现中,谓词作用列如果同时被投影,该列会被读取两次。arrow-rs 对于这种列,会 cache 一下,这样第二次投影列的时候,直接从 cache 里面拿就行了。Cache 的生命周期是 RowGroup 级别,就是用智能指针 hold 住原来的列即可。
零拷贝优化
为了避免不必要的 memcpy,对于定长类型,如整形、浮点型(即内存布局完全一致),arrow-rs 直接把解码后的 Vec<T> 的所有权转移到 Arrow Column 的 Buffer 里面,消除拷贝。
更多详情见:https://arrow.apache.org/blog/2025/12/11/parquet-late-materialization-deep-dive/
参考
这个 issue 汇总了优化:https://github.com/apache/arrow-rs/issues/8000
半年了,终于更新了
你怎么实时奸视