在学习 Iceberg 源码前,我们需要搞清楚 Iceberg 中的各种概念,这样源码看起来才能更有层次感。
所以这篇文章只做一件很纯粹的事情,就是理清 Iceberg 中的名称概念,不做其它阐述。
下面所有的命名不是我自己 YY 来的,而是结合 Iceberg 源码(Java & Rust)推敲出来,你可以直接根据命名找到对应的类。
Table Metadata
Table Metadata 指以 metadata.json 结尾的 json 文件。里面主要描述这个表历史中所有的 Schema、Snapshot、Partition Spec 等等。
{
"format-version" : 2,
"table-uuid" : "a2ac9ff6-d518-4ad0-b61b-c6810045eb67",
"location" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study",
"last-sequence-number" : 4,
"last-updated-ms" : 1745938940494,
"last-column-id" : 3,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "c1",
"required" : false,
"type" : "string"
}, {
"id" : 2,
"name" : "c2",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "dt",
"required" : false,
"type" : "timestamptz"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "dt_day",
"transform" : "day",
"source-id" : 3,
"field-id" : 1000
} ]
} ],
"last-partition-id" : 1000,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "smith",
"write.update.mode" : "merge-on-read",
"write.delete.mode" : "merge-on-read",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : 4806444963926574883,
"refs" : {
"main" : {
"snapshot-id" : 4806444963926574883,
"type" : "branch"
}
},
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 5118870316565804441,
"timestamp-ms" : 1745938901928,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1745938810151",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "2875",
"changed-partition-count" : "3",
"total-records" : "3",
"total-files-size" : "2875",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0",
"engine-version" : "3.5.0",
"app-id" : "local-1745938810151",
"engine-name" : "spark",
"iceberg-version" : "Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)"
},
"manifest-list" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/snap-5118870316565804441-1-ade23eb1-0ec7-4524-a08a-b357cefd2a70.avro",
"schema-id" : 0
}, {
"sequence-number" : 2,
"snapshot-id" : 1413489007574589696,
"parent-snapshot-id" : 5118870316565804441,
"timestamp-ms" : 1745938931306,
"summary" : {
"operation" : "delete",
"spark.app.id" : "local-1745938810151",
"deleted-data-files" : "3",
"deleted-records" : "3",
"removed-files-size" : "2875",
"changed-partition-count" : "3",
"total-records" : "0",
"total-files-size" : "0",
"total-data-files" : "0",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0",
"engine-version" : "3.5.0",
"app-id" : "local-1745938810151",
"engine-name" : "spark",
"iceberg-version" : "Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)"
},
"manifest-list" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/snap-1413489007574589696-1-3257e31e-2e0d-493e-9a97-0963947f80ab.avro",
"schema-id" : 0
}, {
"sequence-number" : 3,
"snapshot-id" : 4041695556892817216,
"parent-snapshot-id" : 1413489007574589696,
"timestamp-ms" : 1745938936497,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1745938810151",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "2874",
"changed-partition-count" : "3",
"total-records" : "3",
"total-files-size" : "2874",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0",
"engine-version" : "3.5.0",
"app-id" : "local-1745938810151",
"engine-name" : "spark",
"iceberg-version" : "Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)"
},
"manifest-list" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/snap-4041695556892817216-1-4afeb033-6066-4c98-95f0-39ea4d264c72.avro",
"schema-id" : 0
}, {
"sequence-number" : 4,
"snapshot-id" : 4806444963926574883,
"parent-snapshot-id" : 4041695556892817216,
"timestamp-ms" : 1745938940494,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1745938810151",
"added-data-files" : "1",
"added-position-delete-files" : "1",
"added-delete-files" : "1",
"added-records" : "1",
"added-files-size" : "2744",
"added-position-deletes" : "1",
"changed-partition-count" : "1",
"total-records" : "4",
"total-files-size" : "5618",
"total-data-files" : "4",
"total-delete-files" : "1",
"total-position-deletes" : "1",
"total-equality-deletes" : "0",
"engine-version" : "3.5.0",
"app-id" : "local-1745938810151",
"engine-name" : "spark",
"iceberg-version" : "Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)"
},
"manifest-list" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/snap-4806444963926574883-1-8ce6c310-e91e-457d-9738-0fd32873f0ca.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"partition-statistics" : [ ],
"snapshot-log" : [ {
"timestamp-ms" : 1745938901928,
"snapshot-id" : 5118870316565804441
}, {
"timestamp-ms" : 1745938931306,
"snapshot-id" : 1413489007574589696
}, {
"timestamp-ms" : 1745938936497,
"snapshot-id" : 4041695556892817216
}, {
"timestamp-ms" : 1745938940494,
"snapshot-id" : 4806444963926574883
} ],
"metadata-log" : [ {
"timestamp-ms" : 1745938894645,
"metadata-file" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1745938901928,
"metadata-file" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/v2.metadata.json"
}, {
"timestamp-ms" : 1745938931306,
"metadata-file" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/v3.metadata.json"
}, {
"timestamp-ms" : 1745938936497,
"metadata-file" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/v4.metadata.json"
} ]
}Snapshot
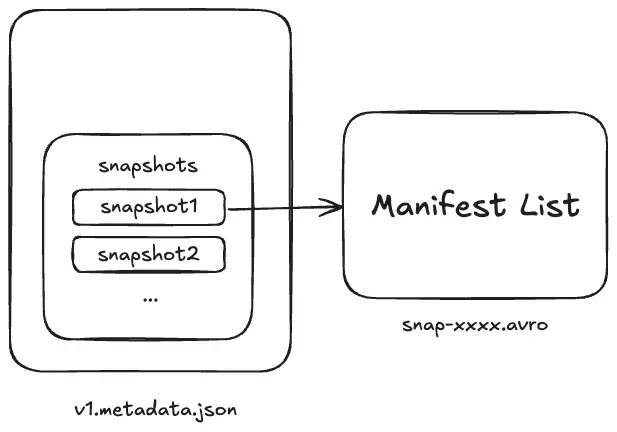
Table Metadata 里面有一个 snapshots 字段,里面包含了所有历史的 Snapshot 信息。
一个 Snapshot 对应一个 Manifest List 文件。你甚至可以认为 Snapshot 和 Manifest List 是等价的。
Manifest List 文件的命名通常是 snap-xxx.avro。
Manifest List
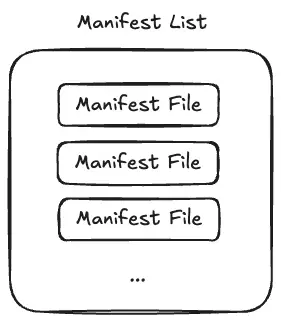
Manifest List 里面存储的是一个数组,数组的每一个元素叫做 Manifest File。你可以简单的认为 Manifest List AVRO 反序列化后的结构是 Array<ManifestFile>。
{
"manifest_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/8ce6c310-e91e-457d-9738-0fd32873f0ca-m0.avro",
"manifest_length" : 7376,
"partition_spec_id" : 0,
"content" : 0,
"sequence_number" : 4,
"min_sequence_number" : 4,
"added_snapshot_id" : 4806444963926574883,
"added_files_count" : 1,
"existing_files_count" : 0,
"deleted_files_count" : 0,
"added_rows_count" : 1,
"existing_rows_count" : 0,
"deleted_rows_count" : 0,
"partitions" : {
"array" : [ {
"contains_null" : false,
"contains_nan" : {
"boolean" : false
},
"lower_bound" : {
"bytes" : "í;\u0000\u0000"
},
"upper_bound" : {
"bytes" : "í;\u0000\u0000"
}
} ]
},
"key_metadata" : null
}
{
"manifest_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/4afeb033-6066-4c98-95f0-39ea4d264c72-m0.avro",
"manifest_length" : 7471,
"partition_spec_id" : 0,
"content" : 0,
"sequence_number" : 3,
"min_sequence_number" : 3,
"added_snapshot_id" : 4041695556892817216,
"added_files_count" : 3,
"existing_files_count" : 0,
"deleted_files_count" : 0,
"added_rows_count" : 3,
"existing_rows_count" : 0,
"deleted_rows_count" : 0,
"partitions" : {
"array" : [ {
"contains_null" : false,
"contains_nan" : {
"boolean" : false
},
"lower_bound" : {
"bytes" : "ë;\u0000\u0000"
},
"upper_bound" : {
"bytes" : "í;\u0000\u0000"
}
} ]
},
"key_metadata" : null
}
{
"manifest_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/8ce6c310-e91e-457d-9738-0fd32873f0ca-m1.avro",
"manifest_length" : 7409,
"partition_spec_id" : 0,
"content" : 1,
"sequence_number" : 4,
"min_sequence_number" : 4,
"added_snapshot_id" : 4806444963926574883,
"added_files_count" : 1,
"existing_files_count" : 0,
"deleted_files_count" : 0,
"added_rows_count" : 1,
"existing_rows_count" : 0,
"deleted_rows_count" : 0,
"partitions" : {
"array" : [ {
"contains_null" : false,
"contains_nan" : {
"boolean" : false
},
"lower_bound" : {
"bytes" : "í;\u0000\u0000"
},
"upper_bound" : {
"bytes" : "í;\u0000\u0000"
}
} ]
},
"key_metadata" : null
}Manifest File
下面这个就是一个 Manifest File 的内容,是从 Manifest List 里面截出来的一小段。
{
"manifest_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/metadata/8ce6c310-e91e-457d-9738-0fd32873f0ca-m1.avro",
"manifest_length" : 7409,
"partition_spec_id" : 0,
"content" : 1,
"sequence_number" : 4,
"min_sequence_number" : 4,
"added_snapshot_id" : 4806444963926574883,
"added_files_count" : 1,
"existing_files_count" : 0,
"deleted_files_count" : 0,
"added_rows_count" : 1,
"existing_rows_count" : 0,
"deleted_rows_count" : 0,
"partitions" : {
"array" : [ {
"contains_null" : false,
"contains_nan" : {
"boolean" : false
},
"lower_bound" : {
"bytes" : "í;\u0000\u0000"
},
"upper_bound" : {
"bytes" : "í;\u0000\u0000"
}
} ]
},
"key_metadata" : null
}可以注意到 Manifest File 上面有一个 content 和一个 partition_spec_id 。
content 表明一个 Manifest File 下所有的文件只能全是 Delete File 或全是 Data File。不可能 Data File 和 Delete File 混用。
partition_spec_id 表明一个 Manifest File 下的所有文件一定都是属于同一个 Partition Spec,不可能说一部分文件是分区变更前写的,一部分是变更后写的。
Manifest
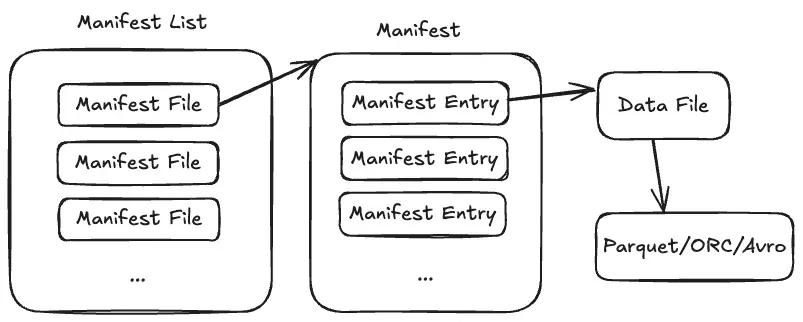
一个 Manifest File 对应一个 Manifest。Manifest File 里面的 manifest_path 路径即是 Manifest 的路径。
Manifest AVRO 反序列化后也是一个数组,数组每一个元素叫做 Manifest Entry,可以简单的认为 Manifest 的结构是 Array<ManifestEntry>
Manifest 的内容如下:
{
"status" : 1,
"snapshot_id" : {
"long" : 5118870316565804441
},
"sequence_number" : null,
"file_sequence_number" : null,
"data_file" : {
"content" : 0,
"file_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/data/dt_day=2012-01-01/00000-3-fc9a6a43-72b6-4723-bda7-c5f77ff047a2-0-00002.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt_day" : {
"int" : 15340
}
},
"record_count" : 1,
"file_size_in_bytes" : 956,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 44
}, {
"key" : 2,
"value" : 44
}, {
"key" : 3,
"value" : 43
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
}, {
"key" : 3,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
}, {
"key" : 3,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "buhao"
}, {
"key" : 2,
"value" : "danny"
}, {
"key" : 3,
"value" : "\u0000Àæyµ\u0004\u0000"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "buhao"
}, {
"key" : 2,
"value" : "danny"
}, {
"key" : 3,
"value" : "\u0000Àæyµ\u0004\u0000"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
},
"referenced_data_file" : null
}
}
{
"status" : 1,
"snapshot_id" : {
"long" : 5118870316565804441
},
"sequence_number" : null,
"file_sequence_number" : null,
"data_file" : {
"content" : 0,
"file_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/data/dt_day=2011-12-31/00000-3-fc9a6a43-72b6-4723-bda7-c5f77ff047a2-0-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt_day" : {
"int" : 15339
}
},
"record_count" : 1,
"file_size_in_bytes" : 956,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 44
}, {
"key" : 2,
"value" : 44
}, {
"key" : 3,
"value" : 43
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
}, {
"key" : 3,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
}, {
"key" : 3,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "nihao"
}, {
"key" : 2,
"value" : "smith"
}, {
"key" : 3,
"value" : "\u0000`\u000Fqeµ\u0004\u0000"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "nihao"
}, {
"key" : 2,
"value" : "smith"
}, {
"key" : 3,
"value" : "\u0000`\u000Fqeµ\u0004\u0000"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
},
"referenced_data_file" : null
}
}Manifest Entry
一个 Manifest Entry 对应一个文件 Data File,Data File 可能是一个真的数据文件,也可能是 Delete File,由 content 决定。file_path 即是指向文件的具体路径。
从上面 Manifest 里面截出来一段 Manifest Entry 如下:
{
"status" : 1,
"snapshot_id" : {
"long" : 5118870316565804441
},
"sequence_number" : null,
"file_sequence_number" : null,
"data_file" : {
"content" : 0,
"file_path" : "/Users/smith/Software/spark-3.5.0-bin-hadoop3/warehouse/test/partition_study/data/dt_day=2011-12-31/00000-3-fc9a6a43-72b6-4723-bda7-c5f77ff047a2-0-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt_day" : {
"int" : 15339
}
},
"record_count" : 1,
"file_size_in_bytes" : 956,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 44
}, {
"key" : 2,
"value" : 44
}, {
"key" : 3,
"value" : 43
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
}, {
"key" : 3,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
}, {
"key" : 3,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "nihao"
}, {
"key" : 2,
"value" : "smith"
}, {
"key" : 3,
"value" : "\u0000`\u000Fqeµ\u0004\u0000"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "nihao"
}, {
"key" : 2,
"value" : "smith"
}, {
"key" : 3,
"value" : "\u0000`\u000Fqeµ\u0004\u0000"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
},
"referenced_data_file" : null
}
}Data File
就是数据文件。有 Parquet、ORC、AVRO 三种文件格式。
Delete File
Delete File 属于 Data File 的一种变种。
表示删除哪些行的文件(就是标记删除的文件)。有 Position Delete 和 Equality Delete 两种。其中 Position Delete 老的实现将会在 Iceberg V3 里面废弃,由 Deletion Vector 替代。
真就梳理啊。。这么看paimon基本上纯抄Iceberg
话说V2 V3有变化吗
肯定有呀,Deletion Vector、血缘啥的。期待后续的文章更新吧。