最近阅读 Hadoop 源码,使用 IDEA 打开 Hadoop,正常导入 maven 依赖后,发现某些类里面总是会报各种类不存在的错误,如下图:
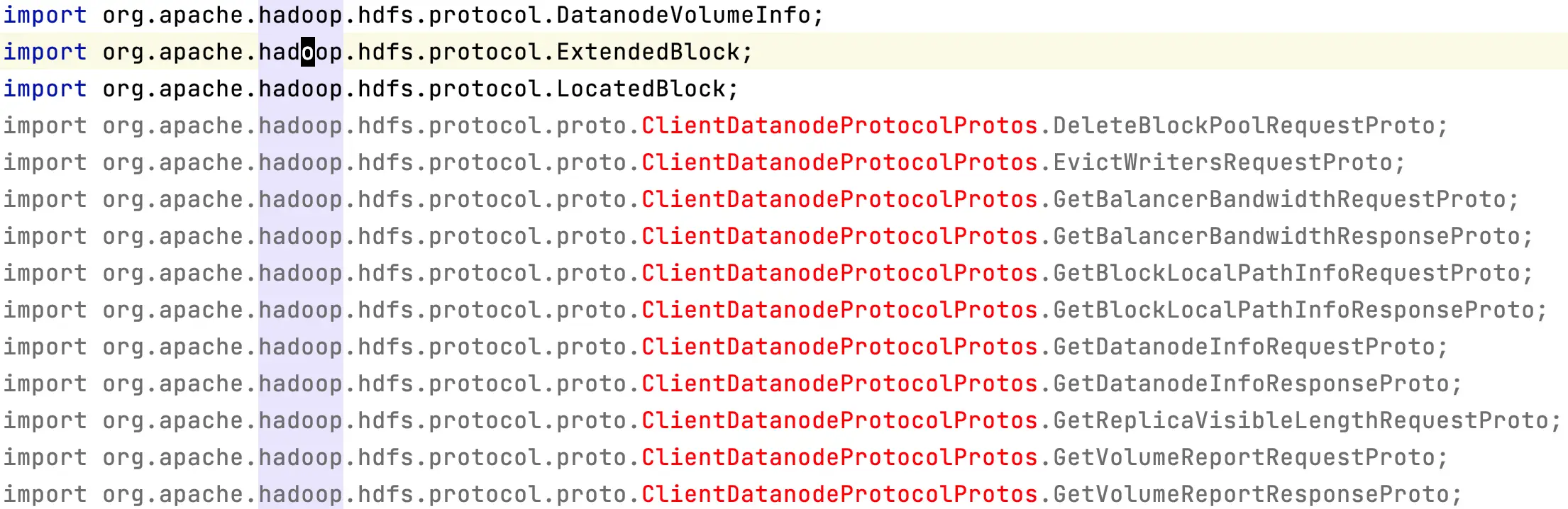
一开始以为是因为我配置了国内 maven 镜像仓库,然后国内镜像仓库里面某些 jar 包没有及时同步,导致的缺失。但是我看了看 maven 中的导入记录,发现并没有报 jar 包找不到的错误。
看了看缺失的类,它们的包名基本都含有 proto 关键字,结合 Hadoop 是使用 protobuf 作为序列化框架,经过我的一番推理,我认为这些缺失的类是需要通过 protobuf 的命令行工具 protoc 产生的,源码里面默认是不带的。
找到了问题,就开始解决,这里我把我的解决思路贴出来,也许不是最好的方法,但是也是目前我能想到最合适的。
我这里不会写明细节上面的操作。
我的 Hadoop 源码为 3.3.0,JDK 版本为 1.8,protobuf 按照源码的要求,安装的是 3.7.1 版本。
方法一, protoc 直接编译,失败
我打算直接使用 protobuf 工具对 .proto 后缀文件进行编译,然而奇怪的事情发生了。这里我以 hadoop-3.3.0-src/hadoop-common-project/hadoop-common/src/main/proto 为例,我使用 protoc --java_out=../ *.proto 命令编译该目录下的所有 .proto 文件。但是报了如下错误:
ProtobufRpcEngine2.proto:46:19: "hadoop.common.RequestHeaderProto.methodName" is already defined in file "ProtobufRpcEngine.proto".
ProtobufRpcEngine2.proto:63:19: "hadoop.common.RequestHeaderProto.declaringClassProtocolName" is already defined in file "ProtobufRpcEngine.proto".
ProtobufRpcEngine2.proto:66:19: "hadoop.common.RequestHeaderProto.clientProtocolVersion" is already defined in file "ProtobufRpcEngine.proto".
ProtobufRpcEngine2.proto:44:9: "hadoop.common.RequestHeaderProto" is already defined in file "ProtobufRpcEngine.proto".大概就是 message 重复了,因为有些 message 同时出现在了不同的 .proto 文件中。那我就单独每个文件执行一次 protoc 命令,这样确实可行,就是累死了,整个 Hadoop 有很多 .proto 文件 ,一个一个编译肯定不行。
此外你看看上面的错误,相同的 message 同时出现在 ProtobufRpcEngine2.proto 和 ProtobufRpcEngine.proto 文件中,那我怎么知道应该使用哪一个 .proto 呢。
方法二,直接 Maven 编译,失败
既然 protoc 命令不行,那我直接按照官方的 BUILDING 文档,直接吧 Hadoop 源码编译一轮,那不就会生成 proto 文件了。我使用的系统是 Mac OS Big Sur,然后我按照 BUILDING 中 Mac 的方法进行编译,然后 mvn 编译的时候老是在 cmake 那里报错,说找不到 zlib,但是我 zlib 明明是有的。而且看到 BUILDING 后面还写着:
Note that building Hadoop 3.1.1/3.1.2/3.2.0 native code from source is broken on macOS. For 3.1.1/3.1.2, you need to manually backport YARN-8622. For 3.2.0, you need to backport both YARN-8622 and YARN-9487 in order to build native code.
瞬间我就放弃了,感觉就算我解决了这个问题,可能后面还有更多的坑。
方法三,远程开发,失败
既然 Mac 不行,然我用 Linux 系统如 Centos 进行编译,然后 IDEA 远程开发不就行了。但是整个 Hadoop 项目过于庞大,每一次 IDEA 同步都要浪费好久的时间,这样肯定也是不行的。因为 IDEA 的 remote development 要求本地和远程都有一份代码。那有没有什么办法能直接编辑远程的代码而不需要本地有吗?
当然有,用 VS Code 的远程开发,然而 VS Code 并没有比 IDEA 好用在哪里。Maven jar 包的识别配置麻烦,而且代码自动推理不如 IDEA 好用。
曲线救国,成功
最后,找了一个方法曲线救国,这里简单说明下:
- 使用自己的一台服务器 or 虚拟机 or Docker 均可,进行编译 Hadoop 源码。
- 我个人是使用了腾讯云的轻量服务器。Docker 的话直接运行源码里面的
start-build-env.sh脚本就行了,然后编译。 - 注意,生成的类是不会直接出现在源码里面,因为是通过 Maven 编译,编译的 Java 文件在
xxx/target/generated-sources/java中。像我用的是腾讯云,可以通过 IDEA 中的 Remote Host 打开远程目录,将那些生成的类直接拖到源码里面即可。
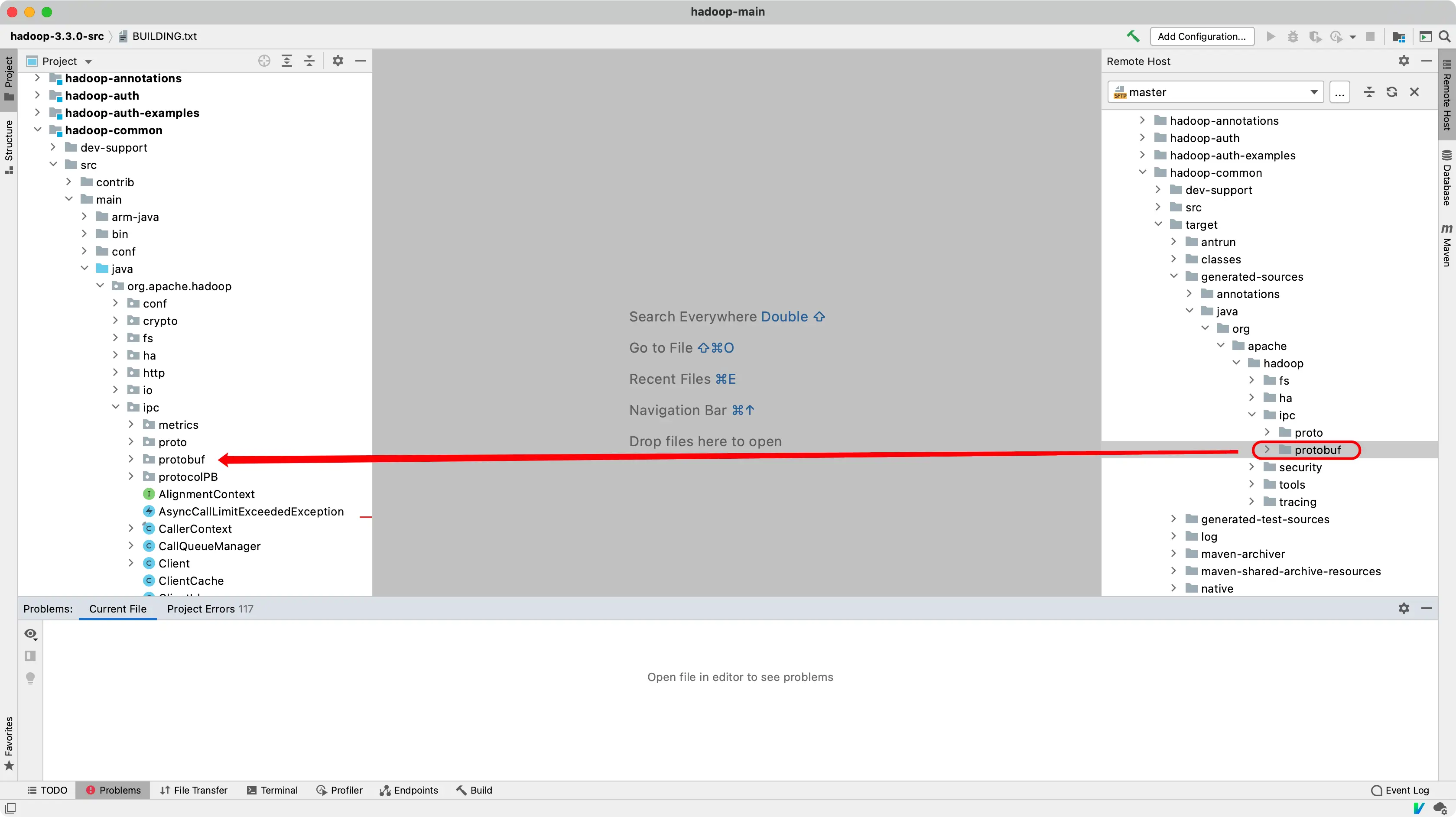
Remote Host是专业版本的功能吗?