最近阅读 HDFS 的源码,看到在 DFSClient 中很多地方用到了 HTrace 这款框架,所以特意学习下。
HTrace 是一款由 Cloudera 开发的分布式追踪框架,在设计上借鉴了 Google 的 Dapper 论文,虽然 HTrace 已经停止了更新,在 Apache 里面孵化失败了,但是它现在任然被 Hadoop 和 HBase 所采用。
HTrace 产生的数据通常不够直观,我们还会使用 Zipkin 进行数据的可视化。
作用
在分布式系统中,用户发送的一个 RPC 请求,会在后台产生多个请求。例如用户通过 HDFS Client 上传一个文件,中间可能涉及到从 Client 到 NameNode,Client 到 DataNode,NameNode 到 DataNode 的 RPC 请求。但是我们该如何追踪这些具体 RPC 请求的性能呢?传统的方法只能监控到 Client 上传文件整一个过程的耗时,而无法捕捉到其间各个请求的性能,从而无法定位性能产生瓶颈的地方。这也就是 HTrace 所需要解决的问题。
术语
Span
HTrace 中追踪的最小单位。一个 Span 表示一个操作所消耗的时间,它包含开始时间,结束时间和描述信息。
TraceScope
TraceScope 管理 Span 的生命周期,当一个 TraceScope 创建,也就代表创建了一个 Span。当 TraceScope 关闭了,也就代表这个 Span 结束了。关闭 TraceScope 后,会把 Span 的信息发送给 SpanReceiver 进行处理。TraceScope 通过 ThreadLocal 保存数据,所以在监控多线程的时候,可以使用 Trace.wrap() 的方式,防止 Span 的数据丢失。
例如原本
Thread t1 = new Thread(new MyRunnable());
// doing something... 改为
Thread t1 = new Thread(Trace.wrap(new MyRunnable()));
// doing something...即可,更多用法,可以看 https://www.scalyr.com/blog/htrace-tutorial-how-to-monitor-distributed-systems/ 。
Tracer
Tracer 提供 API 用于创建 TraceScope。你可以把它当做 log4j 中的 Log,一个项目可以有多个 Tracer 对象,Tracer 是线程安全的,你可以多线程同时访问同一个 Tracer 创建 TraceScope,官方也是推荐这么干的。
Sampler
一个系统中 RPC 产生的次数肯定是很多的,如果我们记录每一个 RPC 请求,则会给系统带来巨大的压力,而且产生过多的数据。所以我们可以通过采样的方法,选择性的进行追踪。
HTrace 提供了如下 Sampler:
- ProbabilitySampler 一定概率进行采样,通过
sampler.fraction进行概率配置。 - AlwaysSampler 一直采样。
- NeverSampler 永不采样。
- CountSampler 每 N 次进行一次采样,N 通过
sampler.frequency进行配置。
SpanReceivers
顾名思义,用于接收 Span 的,HTrace 提供了如下 Receiver:
- LocalFileSpanReceiver 将 Span 信息输出在本地,通过
local.file.span.receiver.path配置输出路径。 - StandardOutSpanReceiver 将 Span 信息输出在控制台。
- ZipkinSpanReceiver 将 Span 信息输出到 Zipkin。
环境搭建
Maven 添加
考虑到我们需要将数据输出到 Zipkin,我们添加如下两个 maven:
<!-- https://mvnrepository.com/artifact/org.apache.htrace/htrace-core4 -->
<dependency>
<groupId>org.apache.htrace</groupId>
<artifactId>htrace-core4</artifactId>
<version>4.2.0-incubating</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.htrace/htrace-zipkin -->
<dependency>
<groupId>org.apache.htrace</groupId>
<artifactId>htrace-zipkin</artifactId>
<version>4.2.0-incubating</version>
</dependency>Zipkin 安装
根据官方文档,下载 Zipkin jar 包,并运行。
注意,运行的时候需添加 COLLECTOR_SCRIBE_ENABLED=true,否则 Zipkin 无法正常接收到来自 HTrace 的数据。因为这种接收方法过于老土,Zipkin 默认是不开启的。
COLLECTOR_SCRIBE_ENABLED=true java -jar zipkin-server-2.23.2-exec.jar访问 127.0.0.1:9411 即可看到 Zipkin 的 WebUI 界面。
代码示例
追踪单机版
配置 Tracer
每一个 Tracer 的创建需要我们自己传入配置信息,例如如下:
Map<String, String> config = new HashMap<>();
config.put("sampler.classes", "org.apache.htrace.core.AlwaysSampler");
config.put("span.receiver.classes", "org.apache.htrace.impl.ZipkinSpanReceiver;org.apache.htrace.core.StandardOutSpanReceiver");
Tracer tracer = new Tracer.Builder("simple").conf(HTraceConfiguration.fromMap(config)).build();这里测试我们使用了 AlwaysSampler,追踪每一次操作。
同时我们添加了两个 SpanReceiver,一个输出到 Zipkin,一个输出到控制台,这里使用 ; 间隔即可。
创建 TraceScope
这里使用了两种创建 TraceScope 的方式
- try catch 因为当 try catch 结束后,会自动关闭 TraceScope,更加优雅。
- 传统方法,需要手动关闭 TraceScope。
下面贴上完整代码:
scope1 和 scope2 分别采用了两种不同的方式创建 TraceScope。
public class SimpleHTrace {
public static void main(String[] args) {
Map<String, String> config = new HashMap<>();
config.put("sampler.classes", "org.apache.htrace.core.AlwaysSampler");
config.put("span.receiver.classes", "org.apache.htrace.impl.ZipkinSpanReceiver;org.apache.htrace.core.StandardOutSpanReceiver");
Tracer tracer = new Tracer.Builder("simple").conf(HTraceConfiguration.fromMap(config)).build();
try (TraceScope scope1 = tracer.newScope("1st operation")) {
System.out.println("Doing 1st operation");
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
TraceScope scope2 = tracer.newScope("2st operation");
System.out.println("Doing 2st operation");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
scope2.close();
tracer.close();
}
}运行可以看到控制台输出如下:
Doing 1st operation
{"a":"33bc155592be3f5022294b89a5000a2a","b":1611226202469,"e":1611226203470,"d":"1st operation","r":"simple/192.168.3.22","p":[]}
Doing 2st operation
{"a":"fe300340f95fcbe5a5b3f71bc904a48c","b":1611226203495,"e":1611226203996,"d":"2st operation","r":"simple/192.168.3.22","p":[]}可以看到每一个 Span 的结果是一串 json 字符串
- a:Span ID
- b:开始时间戳
- e:停止时间戳
- d:scope 名称
- r:tracer ID
- p:父 Span ID
查看 Zipkin 的 WebUI,serviceName 就是我们创建 Tracer 时候取的名字。
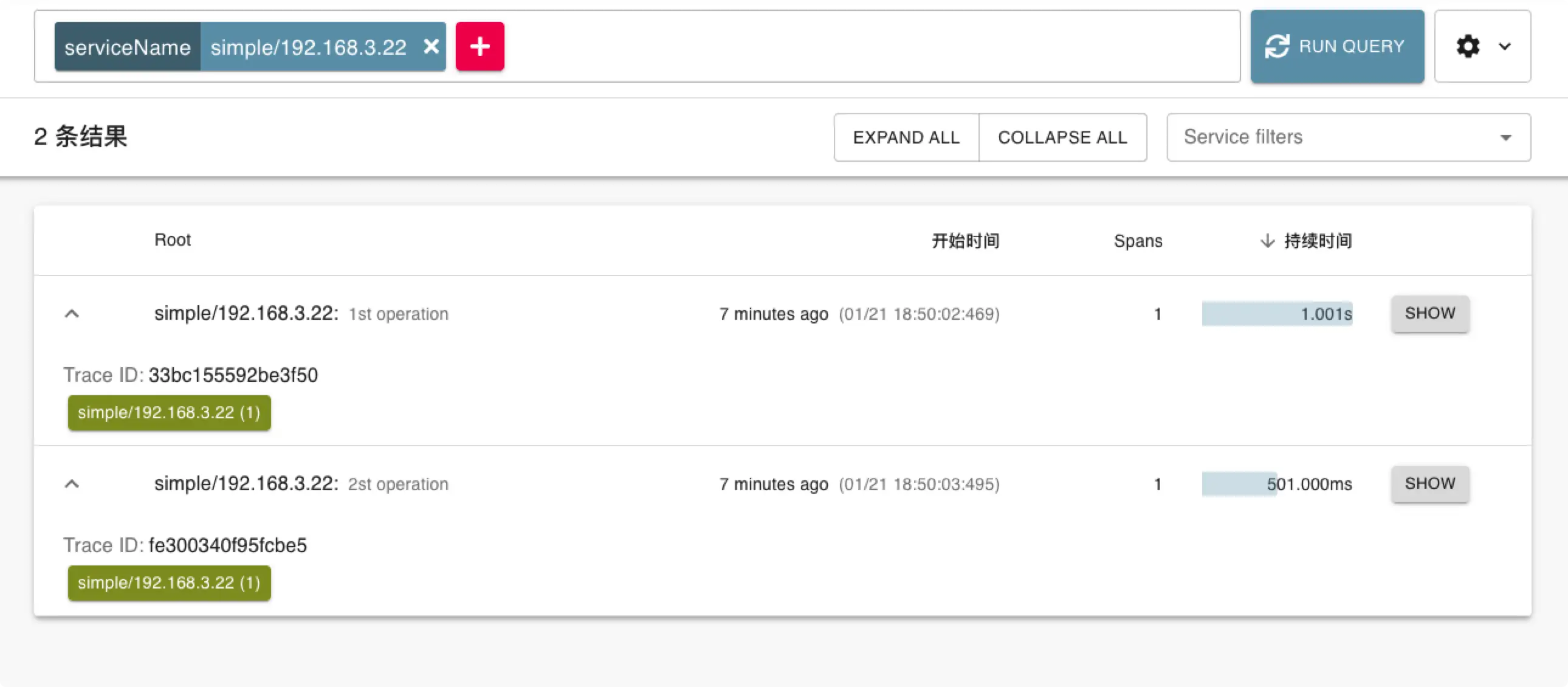
追踪分布式
接下来通过多线程来模拟远程 RPC,并用 HTrace 进行追踪。
在分布式的追踪过程中,因为请求会分布在各个节点,不在同一台电脑上,所以 HTrace 使用 SpanId 来追踪请求。你只需要在每一个 RPC 请求中附带上当前 TraceScope 的 SpanId 就行了,然后在接收端创建新的 TraceScope 时需指定其 parent SpanId 是 RPC 请求传输过来的那一个。具体代码如下:
这里分别模拟了三个过程:Send-RPC -> Receive RPC -> Handle RPC
public class DistributedHTrace {
private static Tracer getTracer() {
Map<String, String> config = new HashMap<>();
config.put("sampler.classes", "org.apache.htrace.core.AlwaysSampler");
config.put("span.receiver.classes", "org.apache.htrace.impl.ZipkinSpanReceiver;org.apache.htrace.core.StandardOutSpanReceiver");
return new Tracer.Builder("Distributed").conf(HTraceConfiguration.fromMap(config)).build();
}
private static Runnable theTask(SpanId parentSpanId) {
Tracer tracer = getTracer();
return new Runnable() {
@Override
public void run() {
SpanId temp = null;
try(TraceScope traceScope = tracer.newScope("Receive RPC", parentSpanId)) {
// 接收 RPC 耗时
Thread.sleep(1000);
temp = traceScope.getSpanId();
} catch (Exception e) {
e.printStackTrace();
}
try(TraceScope traceScope = tracer.newScope("Handle RPC", temp)) {
// 处理 RPC 耗时
Thread.sleep(600);
} catch (Exception e) {
e.printStackTrace();
}
}
};
}
public static void main(String[] args) throws Exception {
Tracer tracer = getTracer();
TraceScope rootScope = tracer.newScope("Send RPC");
Thread.sleep(200); // 发送耗时
Thread t = new Thread(theTask(rootScope.getSpanId()));
t.start();
// 发送完成,关闭 rootScope
rootScope.close();
// 等待所有任务完成
t.join();
tracer.close();
}
}然后我们看 Zipkin,可以看到 3 个过程的具体耗时:

其他
这里只介绍了 HTrace 的简单用法
更多的 HTrace 配置可以看:https://github.com/apache/incubator-retired-htrace/blob/master/src/main/site/markdown/configuration.md
官方写的两篇教程:
第三方写的教程:
https://www.scalyr.com/blog/htrace-tutorial-how-to-monitor-distributed-systems/