之前一直没有深入了解过 Raft 的成员变更,实现也就是在 TinyKV 中搞了一个单步成员变更,以至于在面试的时候,甚至想当然以为成员变更一定要被 apply 后才生效,结果就被挂了。故这里重新梳理一遍,内容是到处扒来的,不一定正确。
直接成员变更存在的问题
如果我们把成员变更当做和普通日志一样,在 apply 时直接应用,可能会使得整个集群产生两个 leader。
当然这些问题只有当原 leader 在成员变更的过程中挂了才会发生,如果一个 leader 自始至终都在,那成员变更也不会出什么问题。
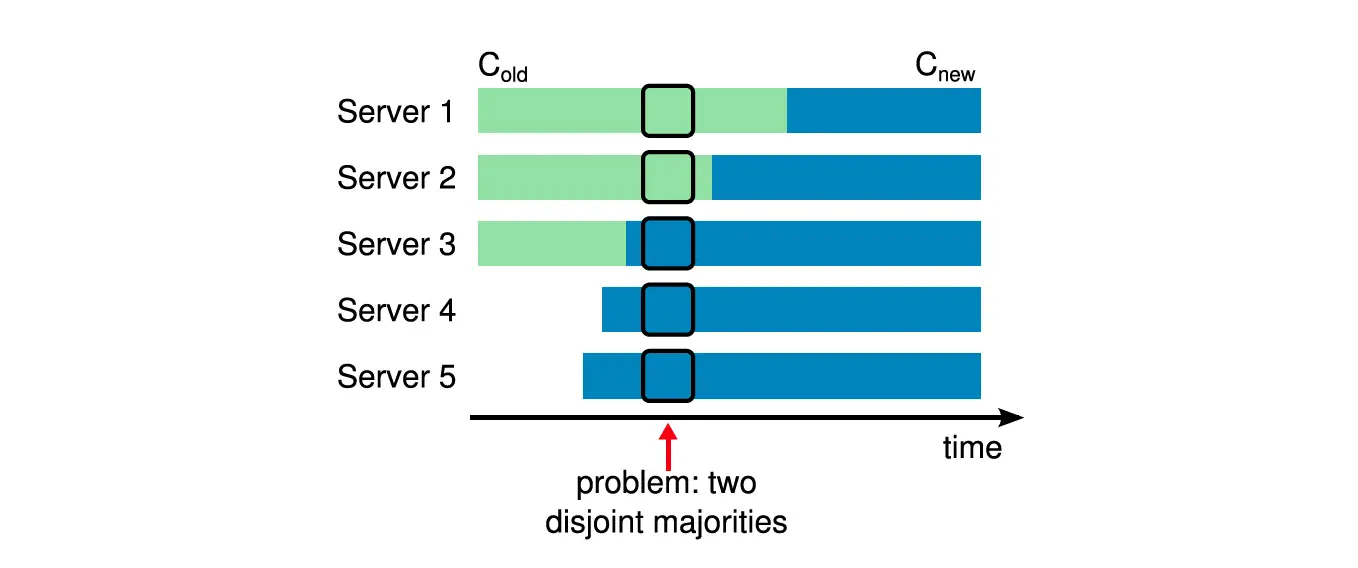
这个图是 Raft paper 里面给的图,很好理解。
从 3 个节点变为 5 个节点的配置,quorum 也从 2 变为了 3。
因为不同节点不可能同时 apply,上面 Server3,Server4,Server5 先使用了新配置 ,而 Server1,Server2比较迟钝,还在用老配置 。
- 假设 Server5 开始选举,赢得 Server3,Server4,Server5 的投票(满足 的 3 quorum),成为 leader。
- 假设 Server1 也开始选举,赢得 Server1,Server2 的投票(满足 的 2 quorum),成为 leader。
自此,整个集群存在两个 leader,会产生一致性问题。
产生这个问题的根本原因是其在成员变更的过程中,产生了两个没有交集的 quorum,使得两个 quorum 各自为营。上面就是 [Server1,Server2] 和 [Server3, Server4, Server5] 各自为一个 quorum。
成员变更配置为什么无需 commit 直接生效
任何一个节点收到了成员变更配置 ConfChange,只要把它持久化了,就可以直接生效,无需和传统日志一样需要先 commit,然后等待 apply 时应用。
我个人从正确性和可用性两点考虑:
1. 正确性
无论我们采用 joint consensus 还是单步成员变更,我们都会保证变更前后的 quorum 存在交集,即保证了整个集群自始至终只会存在一个 leader,以此来保证正确性。
此外我们从宏观角度看,无论处在成员变更的任意阶段,整个集群只有一个 leader,且 leader 被选举出来时必定包含最新的日志(单步成员变更的 bug 就是新 leader 没有最新日志引起的),通过这两个可以看出即使新配置立刻生效,也不会对正确性造成影响。
我个人觉得 ConfChange 和普通的 log 其实是两个东西,互相独立,ConfChange 不一定要满足 log 的特性规定,只不过它们都通过 AppendEntries 同步到各个节点罢了。
上面只是我的个人猜想,不保证正确。
可用性
如果我们规定成员变更只有 committed 后生效,可能会出现可用性故障。
- 假设存在A,B,C,D 四个节点,A 为 Leader,D 因为某种原因一直是故障,当前这个集群仍然是能正常工作的,因为满足 3 quorum。
- Leader A 提出要移除 B 节点,并打算将 同步到 A,B,C,D 四个节点上了。此时 B 节点也失联了,导致 Leader A 只能同步 ConfChange 到 A 和 C 两个节点。因为 2 小于 3 quorum,使得这个 ConfChange 无法被 commit,也就无法生效,而此时整个集群只有两个节点,不满足 quorum 条件,无法处理任何请求。
如果我们假设 ConfChange 收到就应用,第二步变为:
Leader A 提出要移除 B 节点,并打算将 同步到 A,B,C,D 四个节点上了。此时 B 节点也失联了,导致 Leader A 只能同步 ConfChange 到 A 和 C 两个节点。A,C 立即生效了新配置,此时新的 quorum 大小为 2,集群存在两个活跃节点,故其能正常处理请求,commit 正常推进。
小结
很明显,ConfChange 无论何时生效,都不会影响集群的正确性。如果 ConfChange 及时生效,还能使得集群的可用性更高,那么我们何必等到 commit 后生效 ConfChange 呢?
Joint Consensus
Joint Consensus 通过一个中间阶段保证每一步变更的 quorum 比如存在交集。
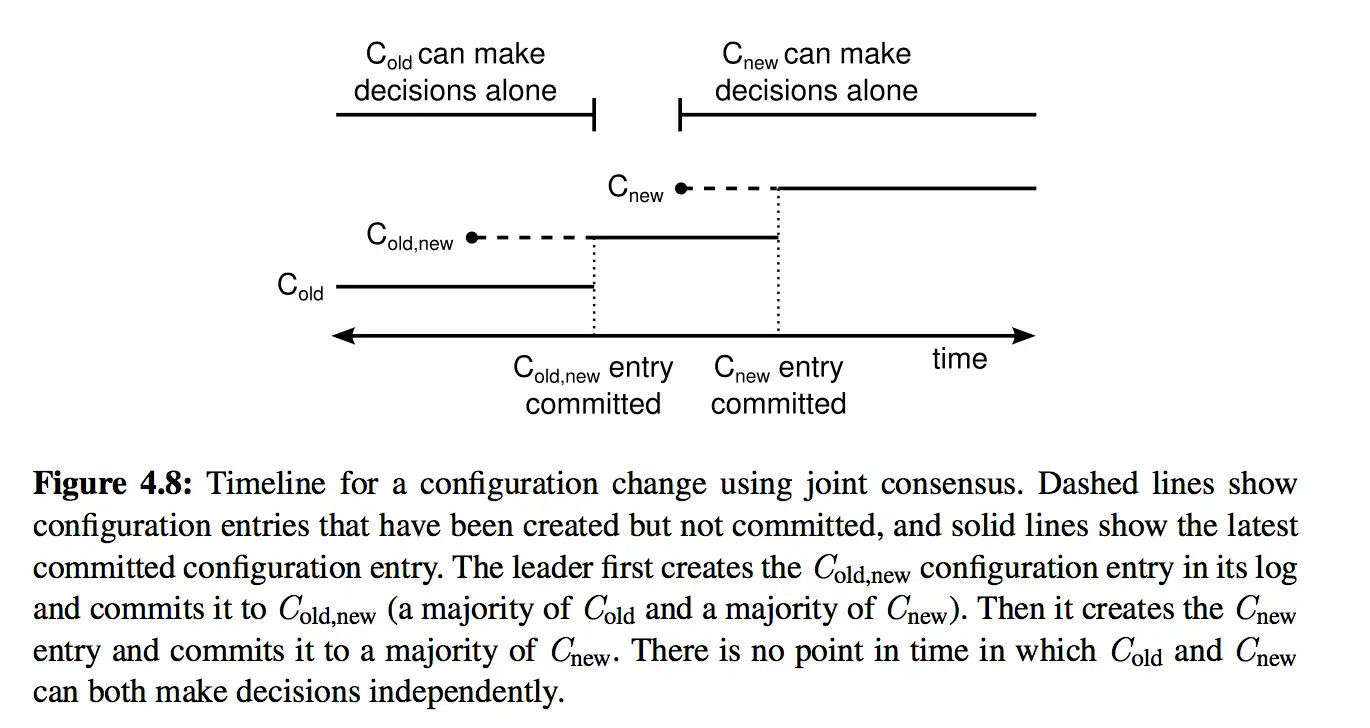
下的 quorum 指的是 的 quorum 加上 的 quorum。
变更过程如下:
- Leader 收到 的成员变更请求,生成一个 的 ConfChang 日志,马上应用该日志,然后将日志通过
AppendEntries请求复制到 Followers 中,收到该 ConfChange 的节点马上应用该配置作为当前节点的配置。 - 当 日志复制到大多数节点上时(这里大多数指的是同时复制到 中的大多数和 中的大多数),那么 的日志就可以 commit 了,在 的 ConfChange 日志被 committed 后,马上创建一个 的 ConfChange 日志,并将该日志通过
AppendEntries请求复制到 Followers 中,收到该 ConfChange 的节点马上应用该配置作为当前节点的配置。 - 一旦 的日志复制到大多数节点上时(这里的大多数指的是 的大多数),那么 的日志就可以提交了,在 日志提交以后,就可以开始下一轮的成员变更了。
可以看出 joint consensus 将成员变更过程划分为多个阶段,每个阶段保证两个配置下的 quorum 存在交集,以此保证不同时出现两个 leader。
- Leader 提出 但是还没有 commit:此时整个集群存在 和 (可能这个节点一直收不到 )两种配置,无论基于哪一种配置选出 leader,其均要通过 的 quorum 同意,故保证单一 leader。如果是 配置的节点成为 leader,那么就回滚 操作;如果是 的节点成为 leader,那么就推进成员变更。
- Leader commit 到提出 之间:此时整个集群存在 和 (可能这个节点一直收不到 )两种配置,leader 一定只会从 配置下选出。因为 committed 的前提是已经得到 和 的 quorum 投票,所以不可能在 下再诞生一个新 leader 了,它无法取得 的 quorum 的投票。你也可以换一种角度理解,因为 已经 commit 了,是一个新的日志,而 因为其没有这个新日志,使得它永远无法赢得投票。
- Leader 提出 到 commit 之间:此时整个集群存在 , , 三种配置。 不可能成为 leader,原因如 2 所示。无论是 还是 成为 leader,其都要获得 quorum 的投票,故保证只会有一个 leader。
- commit 之后,这个时候集群处于 配置下运行,只有 的节点才可以成为 Leader,这个时候就可以开始下一轮的成员变更了。
单步成员变更
Join consensus 有些复杂,Raft 作者搞了个单步成员变更,就是每次只向集群中添加或移除一个节点。比如说以前集群中存在三个节点,现在需要将集群拓展为五个节点,那么就需要一个一个节点的添加,而不是一次添加两个节点。
单步成员变更能保证每一次的变更必然存在 quorum 交集。
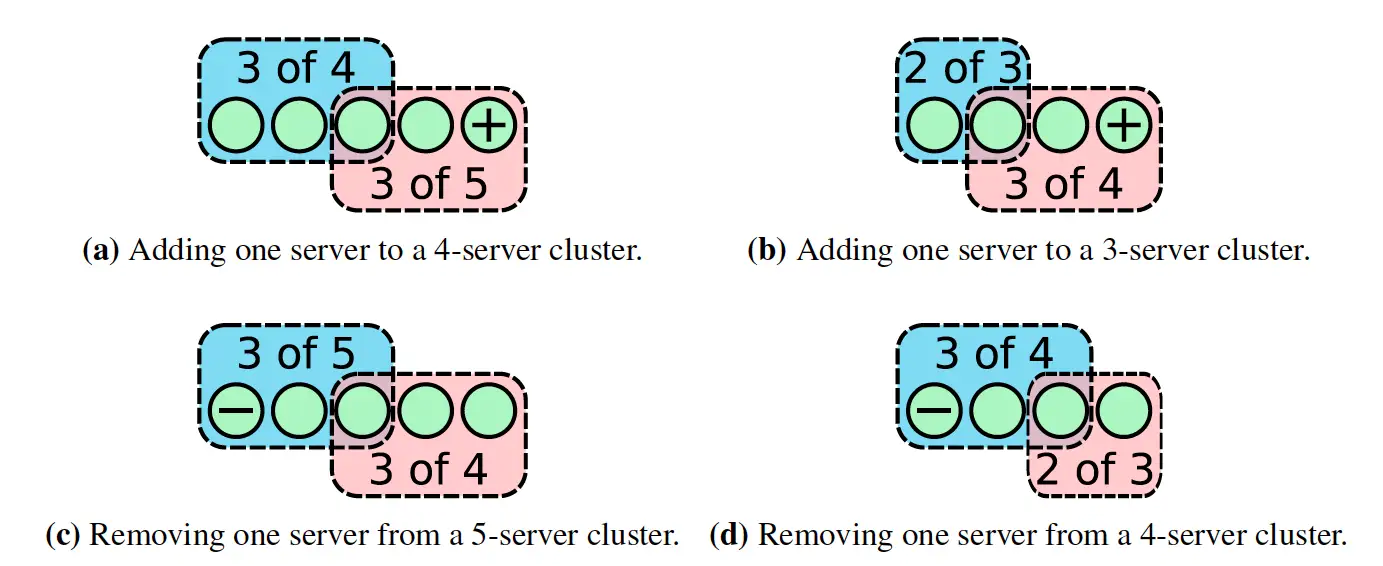
无论集群是奇数还是偶数节点情况下,分别添加或删除一个节点,都没问题。从上图中可以看出,如果每次只增加和删除一个节点,那么 的 quorum 和 的 quorum 之间一定存在交集,也就说是在同一个 term 中, 和 中交集的那一个节点只会进行一次投票,要么投票给 ,要么投票给 ,这样就避免了同一 term 下出现两个 leader。
变更流程如下:
- Leader 提交一个成员变更请求 ,请求的内容为服务节点的是添加还是移除一个节点。
- Leader 在收到请求以后,向日志中追加 的 ConfChange 日志,后续这些日志会随着
AppendEntries同步到所有的 Followers 节点中。 - 当 ConfChange 的日志被添加到日志中是立即生效的。
- 当 ConfChange 的日志被复制到 的大多数服务器上时,那么就可以对其进行 commit。
以上就是整个单节点的变更流程,在日志被提交以后,那么就可以:
- 马上响应客户端,变更已经完成。
- 如果变更过程中移除了服务器,那么服务器可以关机了。
- 可以开始下一轮的成员变更了,注意在上一次变更没有结束之前,是不允许开始下一次变更的。
BUG
单步成员变更是存在 bug 的。
以下是一个单步变更出 bug 的例子, 原成员是 4 节点a,b,c,d。2 个进程分别要加入 u 和加入 v,如果中间出现换主,就会丢失一个已提交的变更:
C₀ = {a, b, c, d}
Cᵤ = C₁ ∪ {u}
Cᵥ = C₁ ∪ {v}
Lᵢ: Leader in term `i`
Fᵢ: Follower in term `i`
☒ : crash
|
u | Cᵤ F₂ Cᵤ
--- | ----------------------------------
a | C₀ L₀ Cᵤ ☒ L₂ Cᵤ
b | C₀ F₀ F₁ F₂ Cᵤ
c | C₀ F₀ F₁ Cᵥ Cᵤ
d | C₀ L₁ Cᵥ ☒ Cᵤ
--- | ----------------------------------
v | Cᵥ time
+-------------------------------------------->
t₁ t₂ t₃ t₄ t₅ t₆ t₇ t₈- t₁:abcd 4节点在 term 0 选出 leader=a, 和 2 个 follower b,c。
- t₂:a 广播一个变更日志
Cᵤ,使用新配置Cᵤ,只发送到 a 和 u,未成功提交。 - t₃:a 宕机。
- t₄:d 在 term 1 被选为 leader,2 个 follower 是 b ,c。
- t₅:d 广播另一个变更日志
Cᵥ,使用新配置Cᵥ,成功提交到 c,d,v。 - t₆:d 宕机。
- t₇:a 在 term 2 重新选为 leader,它本地能看到的新配置
Cᵤ。 - t₈:a 同步本地的日志给所有人,造成已提交的
Cᵥ丢失。
出现问题的根本原因就是 a 不应该在 t₇ 时成为 leader,按道理它没有最新的数据,只是凑巧 b 在 t₅ 时没有被同步数据罢了,否则它根本获得不了 b 的投票。
作者给出了这个问题的修正方法,步骤很简单,跟 Raft 的 commit 条件如出一辙:新 leader 必须提交一条自己的 term 的 no-op 日志, 才允许接着变更日志。
在上面这个例子中,对应的就是 L₁ 必须 commit 一条 no-op 的日志后才能变更日志,也就是让 b 上存在最新的日志, 以便 a 能在 t₇ 发现自己的日志是旧的,不成为 leader。
更多可以参考:https://zhuanlan.zhihu.com/p/342319702
存在的问题
可用性
新服务器追赶日志
在添加服务器以后,如果新的服务器需要花很长时间来追赶日志,那么这段时间内服务不可用。
如下图所示:
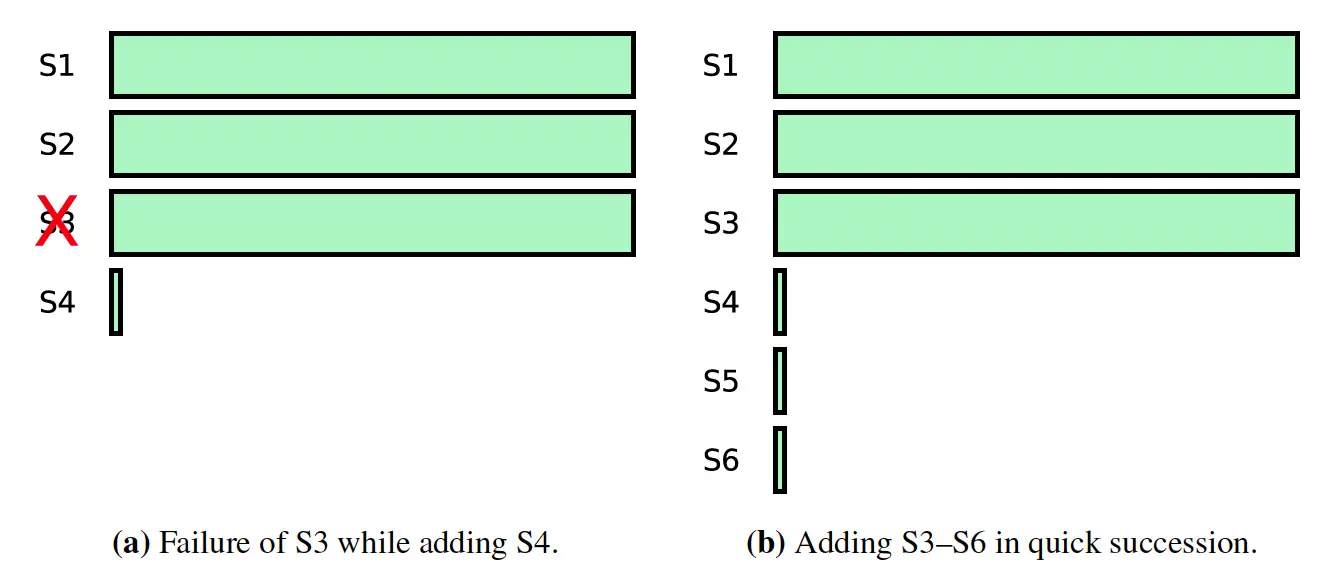
- 左图:向集群中添加新的服务器 S4 以后,S3 宕机了,那么此时因为 S4 需要追赶日志,此时整个集群不可用。
- 右图:向集群中添加多个服务器,那么添加以后 quorum 肯定是包含新的服务器的,那么此时S4,S5,S6需要追赶日志,肯定也是不可用的。
可以通过在集群中加入新的角色 Leaner,Leaner 只对集群的日志进行复制,并不参加投票和提交决定,在需要添加新节点的情况下,先添加 Leaner ,等待其同步完成时,再执行真正的成员变更操作。
还有一种方法是多个 rounds 追赶日志,感觉用的人不多,这里不阐述。
单步成员变更可能引起的可用性问题
a b c
---- ---- ----
DC-1 DC-2 DC-3
| add `d` in DC-1
v
a b c partitioned a | b c
d DAMN IT !!! d |
---- ---- ---- ------------> ---- | ---- ----
DC-1 DC-2 DC-3 DC-1 | DC-2 DC-3
| remove `a`,
| WELL DONE !!!
v
b c
d
---- ---- ----
DC-1 DC-2 DC-3正常情况下, 任意一个机房和外界连接中断, 都可以用剩下的 2 个机房选出 leader 继续工作。
在成员变更过程中, 例如上面需要将 DC-1 中的 a 节点迁移到 d 节点, 中间状态 DC-1 有 a d 2个节点。这时如果 DC-1 跟外界联系中断,由于 4 节点的 quorum 需要至少3个节点, 导致 DC-1 内部无法选出 leader,DC-2 和 DC-3 也不能一起选出一个 leader。
在 4 节点变更的中间状态中, 任一 quorum 都必须包含 DC-1, 从而 DC-1 就成了系统的故障单点。
解决办法:给节点加权重?算了,不可用就不可用吧,不会引起一致性问题就行了。
Leader 移除自己
如果 不包含 leader 自己本身,如果直接应用对应的日志,会导致如下问题:
- ConfChange 的日志尚未复制到 中其他节点,然后 leader 自己挂了,那不是相当于你这个移除操作根本不存在。
- Leader 退位成为 Follower 后可能因为超时重新成为 Leader,因为该节点上的日志是最新的,因为日志的安全性,该节点并不会为其他节点投票。
可以采取如下两种方法:
- 当发现 不包含自己时,先使用 Leader Transfer 转移 leader,再应用该日志。
- 等到 commit 后,再移除自己。此时集群会自己超时重新选举新的 leader,因为 已经 commit, 已经被复制到了大多数集群上了,所以即使原来的 leader 超时选举,也无法成为 leader。
来自中断服务器的干扰
当一个服务器从新配置中被移除,但还没有关机,因为没有 leader 会给它发送心跳,它自己会尝试增加 term 开始选举。在 中的 leader 收到更大 term 的投票,会自动退化成了 follower,然后重新选举。虽然那个被移除的机器永远无法成为 leader,但是它会不断的干扰正常集群的工作。
可以采用 PreVote 方法解决,一个服务器开始选举时,先发起 PreVote,如果得到半数以上的同意,再发起投票。
在 PreVote 算法中,Candidate 首先要确认自己能赢得集群中大多数节点的投票,这样才会把自己的 term 增加,发起真正的投票。其他投票节点同意给它投票的条件是(同时满足下面两个条件):
- 没有收到有效领导的心跳,至少有一次选举超时。
- Candidate 的日志足够新(Term 更大,或者 Term 相同 Raft log index 更大)。
Joint Consensus 如果前后完全没有节点重合会怎么样
这里感觉有问题,没被 commit 的日志有可能会被删除的,一个节点 apply 一个被删除的日志看起来是危险的。例如 C apply 了移除 B 节点这个日志,但是后面由于种种原因 移除 B 节点这个 log 没被 commit 并且以后也不会 commit,那么 C 的 peers 就乱了(极端情况下,如果 B 后面成为了 Leader,那么 C 就不会再收到 B 的日志和心跳)。
v 怎么能收到,v 是新配置变更后新加的节点。只有先 commit no-op 成功后,才能进行配置变更。所以 L₁ commit no-op 的前提是 b 和 c 节点都收到 no-op。
明白了,谢谢大哥,之前大意了🤣