Introduction
Log-Structured File System (LFS)发明的背景就是建立在 CPU 高速发展,磁盘读取写入速度极速发展,单位内存越来越便宜,而磁盘的寻道耗时(受限于物理因素,快不起来)没有什么进步的情况下。
LFS 假设文件可以缓存在内存中,而且随着内存变大,能缓存的文件越多。而写入文件终究还是要写入磁盘,所以只需要优化好磁盘的写入操作,就能极大的提升性能。
LFS 将所有写入的文件缓存在内存中,汇聚成一个顺序结构 log,然后一次性写入磁盘,这样能够最大限度使用磁盘的写入性能。
因为 LFS 都是顺序写入,所以它的 crash recovery 更加迅速,相比于传统文件系统需要扫描整个磁盘,LFS 只需要最近新增的 log 即可(看看最新增的几个 log 是否正常就行了)。
Design
LFS 的核心思想就是先将一系列文件和其 metadata 写入缓存中(包含 data blocks,文件属性,index blocks,目录等信息),然后汇集成一个 log,通过一次磁盘写入操作直接全部写入磁盘,最大程度上利用磁盘的带宽。针对很多小文件写入的场景,LFS 可以将很多小的、随机同步写过程转换为一次大的,异步写过程(为什么叫异步?因为相对于应用来说,虽然你文件没有写入磁盘还在内存中,但是你可以直接告诉用户已经写入成功,反正过会会写入磁盘。),这样可以几乎 100% 利用磁盘的带宽。
当然,如果你写入的文件还在内存中时,系统崩溃了,那这些数据就没了。LFS 也在自己的论文中假设这种崩溃的发生不是频繁的,而且用户接受最近几秒的数据丢失。
虽然 LFS 的核心思想很简单,但是要解决两个重要问题:
- 如何从磁盘中的 log 读取文件?
- 如何管理磁盘的空闲空间,确保有足够的空间存放每一次写入的新数据?
File Location and Reading
在文件的读取性能上,LFS 的目标是持平或超越 FFS 的读取性能。LFS 使用和 FFS 一样的基本结构(inode….)。在 LFS 中,只要读取到了该文件的 inode,后序的读取操作就和 FFS 一样了,也会涉及到随机读。不过别忘了 LFS 的假设,就是内存越来越便宜,大家的内存越来越大,大多数的读取操作都能够直接从缓存中读取。
在 FFS 中,所有的 inode 的位置都是固定的,在每个 cylinder group 中都有固定的 inode 区域(在磁盘格式化的时候就已经确定好了),只要给出文件的 inode 编号,就能计算出该 inode 在哪个 cylinder group,inode table 中的第几个,从而获得文件的 inode。
然后,LFS 没有放置 inode 在固定的位置,inode 每次都是随 log 一道写入磁盘。在每一个 log 中,LFS 使用 inode map 这种结构维护 inode 的位置(仅限该 log 中的 inode)。你可以把 inode map 想象成一种结构,你只要输入 inode number,它会直接返回给你该 inode 的地址。inode map 非常紧凑,可以被缓存在内存中,这样搜索指定 inode number 时不怎么需要访问磁盘。但是,我们该如何寻找 inode map?LFS 维护了一块磁盘上的固定区域叫 checkpoint region(有两个,磁盘开头一个,结尾以后,后面会讲原因),这里面存放着这块磁盘中所有 inode map 的位置。磁盘在挂载时,首先会读取 checkpoint region,然后将其指向的所有 inode map 都缓存在内存中。
可以看看下面的图加深对每一个 log 结构的理解,图中标的是 Segment 0 和 Segment 1,但是个人认为这里叫 log 0 和 log 1 更加合适点。
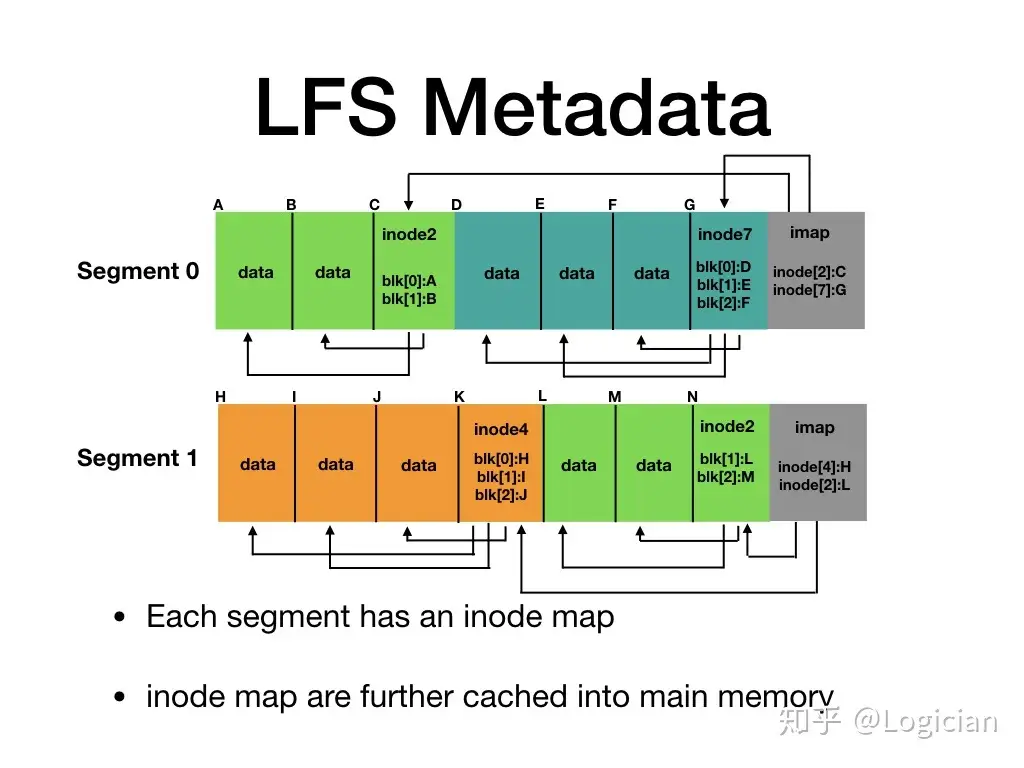
Free Space Management: Segments
LFS 每一次写入 log 都会直接追加在现有 log 的后面,随着时间的推移(前面一些不需要的 log 被删除),会使得磁盘的剩余空间被碎片化,难以被利用。
文件系统有两种方法处理碎片化的空间,分别是 threading 和 copying。
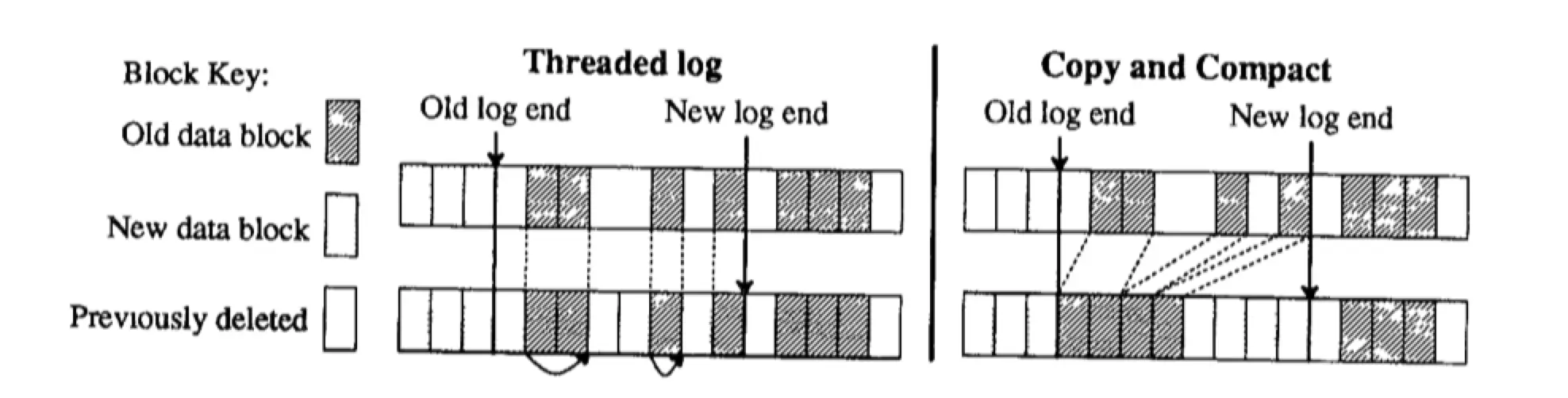
Threading:顾名思义,利用指针,将空闲空间串起来。但是这种方法并没有改善数据在物理层面的碎片化,反而会加剧碎片化的程度。
Copying:就是把零散的数据通过复制移动形成一个紧凑的结果,但是这种方法的缺点就是耗费系统资源。
LFS 同时使用了 threading 和 copying 两种方法。LFS 将磁盘划分为多个大小固定(较大,通常为 512KB 或 1MB)的区域叫 segment。每一个 segment 中的数据都是顺序写入。只有当 segment 中所有所有的 live data 都移出后,这个 segment 才能够被覆盖新内容(这是 Copying)。不同的 segment 之间使用指针相连(这是 Threading)。Segment 的大小足够大,能够使该 segment 的传输时间远大于磁盘的寻道时间。
这里有一点困扰了我,我具体的说说:
论文中的说每一次写入的数据都是追加的,我一开始直观的感觉就是追加在磁盘的后面,但是这样有一个问题,假设 segment $K$ 被清理,变成一块空的区域,为了确保未来的数据追加有足够的空间,我们需要将 $K$ 以后的所有 segment 都向前移动一位,但是这样无疑需要消耗大量的资源。
所以根据我对论文的理解,实际上 LFS 先将磁盘划分为多个 segment,然后使用指针相连,形成类似链表的结构。然后当某个 segment 被清理后,LFS 只是修改了 segment 的指针链接(类似于将链表中的一个节点移除挪到最后),将这个 segment 移到逻辑上面的最后面(其实这个 segment 在磁盘中的物理地址并不一定是最后),这样清理了这个 segment 也不需要把后面所有的 segment 都向前移动,这样也符合的论文中 Threading 的概念。所以每次追加新数据也实际上是追加在逻辑上的最后。
也许你会问这种和随机读有什么区别,毕竟在物理层面上并不连续。但是要注意,我们都是以 segment 为单位进行操作,而且一个 segment 足够大,可以抵消磁盘寻道时间的耗时,$ReadTime >> SeekTime$ 。
Segment 和 log 之间的关系?
说实话,我也不清楚,论文里面也没有明确说。我觉得这里可以认为一个 segment 包含多个 log 或者一个 segment 里面就一个 log,其实这个影响都不大。
Segment Cleaning Mechanism
将 live data 从一个 segment 移出汇聚成一个新的 segment 的过程叫 segment cleaning。
Segment cleaning 分三个步骤:
- 一次性读取 $M$ 个 segment 到内存中。
- 筛选出 live data,汇集成 $N$ 个 segment,并写入干净的 segment 中,其中 $N < M$。
- 将之前读取的 segment 标记为干净,可以用作以后存放新数据使用。
但是,我们该如何判断数据是不是 live data 呢?
LFS 在每个 segment 中提供了一个 segment summary block,在 segment summary block 中存放了该 segment 中每个 data block 所属文件的的 inode 编号和在其文件中的偏移量。通过这些信息,我们就可以判断某一个 data block 是不是 live 的。
假设一个 data block $D$ ,在磁盘中的地址为 $A$,它所属的文件 inode 编号为 $N$,它在该文件中的偏移量为 $T$。检验过程如下:
- 通过 inode map 查询编号为 $N$ 的 inode,返回该 inode 的地址(inode map 在内存中,无需读取磁盘)。
- 通过 inode 将整个文件读取出来到内存中(也许这个文件已经在缓存中了,那还省了寻道时间)。
- 根据偏移量 $T$ 找到对应的 data block。
- 将找到的 data block 的地址和该 segment 中 data block $D$ 的地址进行对比,如果一致,则代表 data block $D$ 是 live 的,否则说明该数据是垃圾,可以被丢弃。
为了加速这一过程,LFS 做了一个优化。当文件被裁剪到 0 或被删除时,LFS 会增加该文件在 inode map 中的 version number。同时 segment summary block 中也有保存 inode 的 version number,这样当判断 data block 是否为垃圾时,可以直接先比较 version number,如果 inode map 中的 version number 大于 segment summary block 中的 version number,则该 inode 对应的所有 data block 就是垃圾,不需要后序的查找该 inode 所对应的文件,通过偏移量拿到指定 data block,比较地址的一系列操作。
为什么只有删除文件或被裁剪到 0 才增加 version number?
如果是在原有文件上面增加的话,则代表有些原有的 data block 是还有用的,如果用这种方法就一棍子打死全部的 data block 了。
同理,如果裁剪文件没有到 0 的话,意味着有些 data block 还是被使用中,故也不能使用这种方法。
Segment Cleaning Policies
知道了 segment cleaning 的机制,我们还要解决两个问题,何时清理 segment?清理哪些 segment?
决定何时清理 segment 很简单,我们可以设置一个线程循环清理,或当系统在空闲状态时,或当磁盘快满的时候进行清理。
关于清理哪些数据,LFS 将 segment 划分为冷热数据。对于冷数据,LFS 会尽可能先清理。对于热数据,因为热数据变换十分频繁,LFS 会稍微拖延点时间清理(这样子可以一波多清理一些数据)。
Crash Recovery
LFS 能够处理的 crash recovery 只有在两个环节,一个是在写入 checkpoint region 时,还有一个是写入 log 时。如果当 LFS 还在将数据放在内存中准备汇集成一个 long 时崩溃的话,那数据就没了。
Checkpoint Region
LFS 会周期性的更新 checkpoint region,一般是 30 秒(每次更新文件后,更新的 checkpoint region 是在内存中的,LFS 周期性的会把 checkpoint region 写入磁盘)。为了确保 checkpoint region 更新的原子性,在更新 checkpoint region 时,先在头写入一个时间戳,然后是内容,在结尾写入一个时间戳。同时 LFS 在磁盘中维护了两个 checkpoint region,一个在磁盘的头部,一个在尾部,两边轮流交替写。当系统崩溃了,LFS 会优先使用时间戳最新的 checkpoint region。在使用 checkpoint region 前,LFS 还会检查其完整性,通过校验头尾的时间戳是否正常(尾的时间戳>头的时间戳,且两边都有时间戳),否则使用另一边的 checkpoint region。
Segment
如果有的 segment 已经写入完成,但是 checkpoint region 来不及更新,或者内存中的 checkpoint region 更新了没有写入磁盘。LFS 采用 roll forward 的方法。首先读取 checkpoint region,获得磁盘中最新写入的 log,然后向后读取,看是否存在有效的 segment,如果存在有效的 segment,则读取其 inode map,然后更新到 checkpoint region 中。
参考文献
https://zhuanlan.zhihu.com/p/41358013
http://www.eecs.harvard.edu/~cs161/notes/lfs.pdf