Fast File System(FFS)一个具有里程碑意义的文件系统。它没有修改上层调用的 API,例如( open(), read(), write() 等等),而修改了内部实现,提升文件系统的效率。基本此后所有的文件系统都基于这种模式进行开发。
Old Unix File System
再开始介绍 Fast File System之前,我们简单介绍下 Old Unix File System。如图:

磁盘开头是 super block(S),包含了整个文件系统的信息,后面则是存放 inode 的区域。剩下的大多数地方为 data block。
这种简单粗暴的设计在代码上很容易实现,但是它有一个致命的问题,就是当文件系统运行时间增长,频繁的创建和删除之后,文件系统的性能会大幅度下降(因为文件在 data block 中不再连续,磁盘碎片化严重)。产生这种情况的原因是因为 Old Unix File System 把磁盘当做一个可以随机读取的内存,没有考虑磁盘的特性。
如图,现在 data block 中充满了 A,B,C,D 的数据

我们删除 B,D 后,变成:

之后我们在分配 E (大小为 4 个 block):

可以看到,E 文件在磁盘中的分布不再连续,意味着我们需要两次寻道才能读取完成 E,无法发挥出磁盘顺序读写的全部性能。
此外,Old Unix File System 中每个 block 的大小为 512 bytes,这会使得磁盘中传输效率低下,而且耗费更多次数的定位。虽然小的 block size 意味着小的 internal fragmentation (waste within the block) (一个 block 中的空间浪费,例如将 400 bytes 的文件放入一个 512 bytes 的 block 中,则产生 112 bytes 的浪费,这 112 bytes 无法再次被利用)。
FFS Organization
- 一个磁盘可以拥有多个文件系统(就是现在的磁盘分区,你可以在不同的分区中使用不同的文件系统),每一个文件系统通过 superblock 描述。Superblock 位于每一个文件系统的开头。因为 superblock 含有文件系统的关键信息,所以它会有多份备份。Superblock 在文件系统被创建以后,就不会在发生修改。备份的 Superblock 正常情况下不会被引用,除非开头的 superblock 损坏。
- 为了确保创建的文件有 $2^{32}$ bytes(通过两层间接引用 two levels of indirection),FFS 的最小 block size 为 4096 bytes。文件系统的 block size 要求为 2 的 n 次方,且 $BlockSize \geq 4096Bytes$ 。文件系统的 block size 必须在文件系统创建的时候被确定,且后期不得修改,除非重新格式化文件系统。
- 将硬盘划分为一个或多个 cylinder groups 。一个 cylinder group 包含一个或多个连续的磁盘柱面。如图:相同颜色的形成一个柱面,多个连续的柱面组成一个 cylinder group。
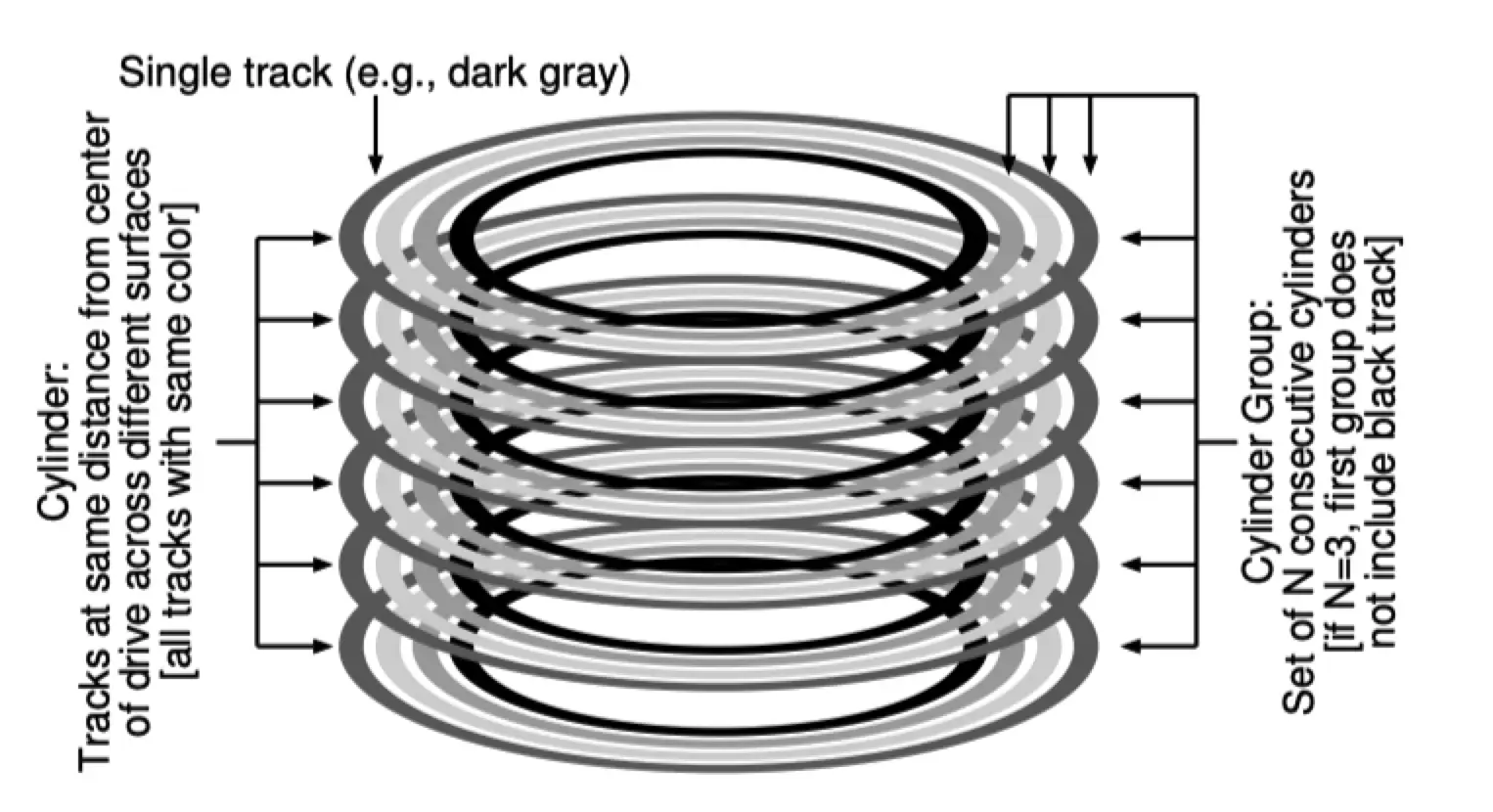
- 每一个 cylinder group 均有 superblock 备份,存放 inodes 的空间,一个描述该 cylinder group 中可用 data block的 bitmap,一个描述该 cylinder group 中可用 inode 的 bitmap。FFS 使用bitmap 替代了传统的 free list(链表)。每一个 cylinder group 中的 inode 数量在创建文件系统的时候就已经确定。默认策略是该 cylinder group 空间中每 2048 bytes 生成一个 inode。因为最小的 $BlockSize = 4096Bytes$,所以确保 inode 的数量远大于该 cylinder groups 中 block 的数量。这么做的考虑是因为有时候目录也是一个 inode,所以要确保 inode 足够使用。Cylinder group 结构如下:

S 为 superblock,ib 为 inode bit map,db 为 data block bit map,Inodes 为存放 inode 的区域,创建文件系统的时候就已经确定。Data 为 data block,用于存放数据。
- 我们可以发现每个 Cylinder group 的关键信息都保存在开头,如果采用这种方法,意味着所有的重要信息(superblock,inode bitmap, data block bitmap)均在最顶部的盘片上面,此时如果最顶部的盘片损坏,则意味着整个文件系统的报废,所有的 superblock 都没了。所以 FFS 为了防止这种情况的发生,每一个 cylinder group 中的关键信息的起始位置是不同的。比如最外圈的 allocation group 关键信息从 $block = 0$ 开始,里面一圈的从 $block=1$ 开始,以此类推。使得关键信息呈螺旋保存在硬盘中(这样避免了所有关键信息都不会在一个盘片上)。除了第一个 cylinder group 中的关键信息在开头,后面的都有一定的偏移量。在有偏移量的 cylinder group 中,开头到关键信息这部分空间用于充当 data block 的一部分,不会白白浪费。
不过现在,已经不需要这种方法了。因为现代磁盘驱动器不会再提供足够的信息来让文件系统判断他们在用哪个柱面。磁盘驱动器只会提供逻辑上面的地址,隐藏了物理地址细节(简化了开发)。所以现代文件系统例如 ext2, ext3, ext4 都不叫 cylinder group 了,取而代之叫 block groups,毕竟柱面的概念被隐藏了。
Optimizing Storage Utilization
$BlockSize=4096Bytes$ 能够极大的提升吞吐量。相比于 $BlockSize = 1024Bytes$,4096 bytes 的 block size 读取一次相当于 1024 的读取 4 次,极大的提升了吞吐量。如果一个大文件,因为 block size 大,可以使得所有数据都在一个柱面上,这样只需要一次寻道即可完成整个文件的读取。(文件大小等于 4096 Bytes * 磁头数)。
但是大的 block size 也有坏处,因为 Unix 系统中有很多不规则的小文件(小于 4096 Bytes),如图:
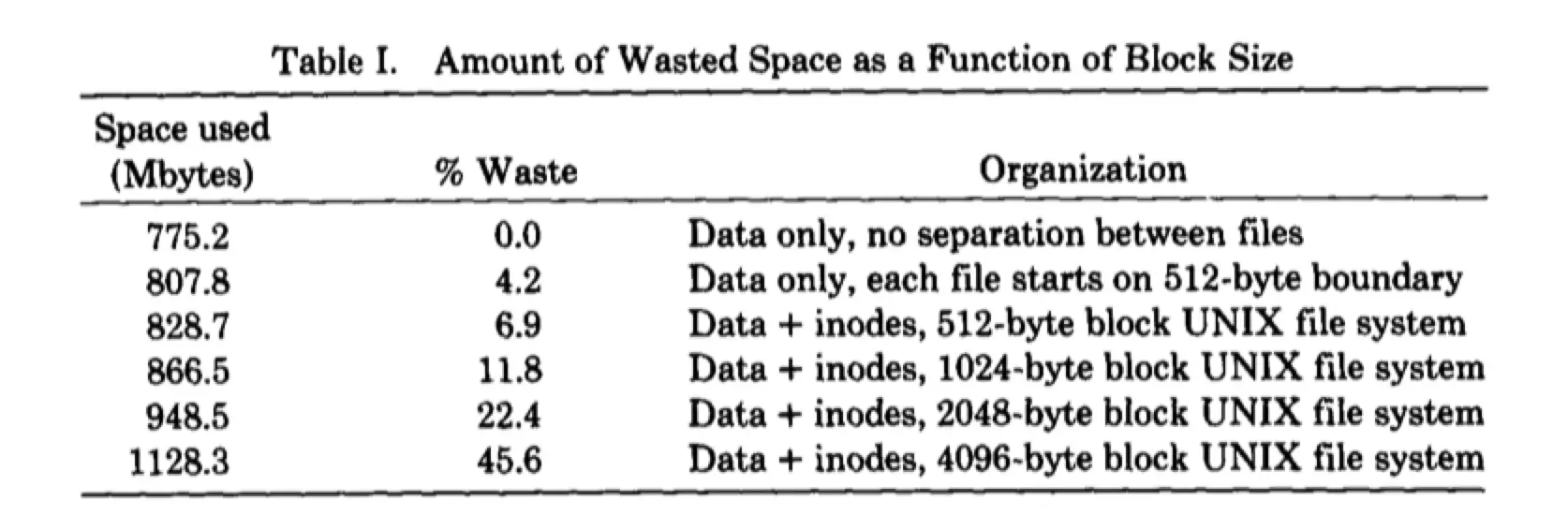
可以看到 block size 越大,空间的浪费率越高。
为了避免大 block size 存储小文件造成的空间浪费,FFS 会将一个 block 均分为多个 fragment(分成 2,4 或 8 个)。最小的 fragment size 必须大于磁盘的 sector size (sector size 通常为 512 bytes,取决于磁盘的物理性质 )。为了记录 fragment 的使用情况, data block bitmap 记录的可用空间需要精确到 fragment 级别。
下图示例是 $BlockSize = 4096Bytes$, $FragmentSize = 1024Bytes$ 下的数据分布:
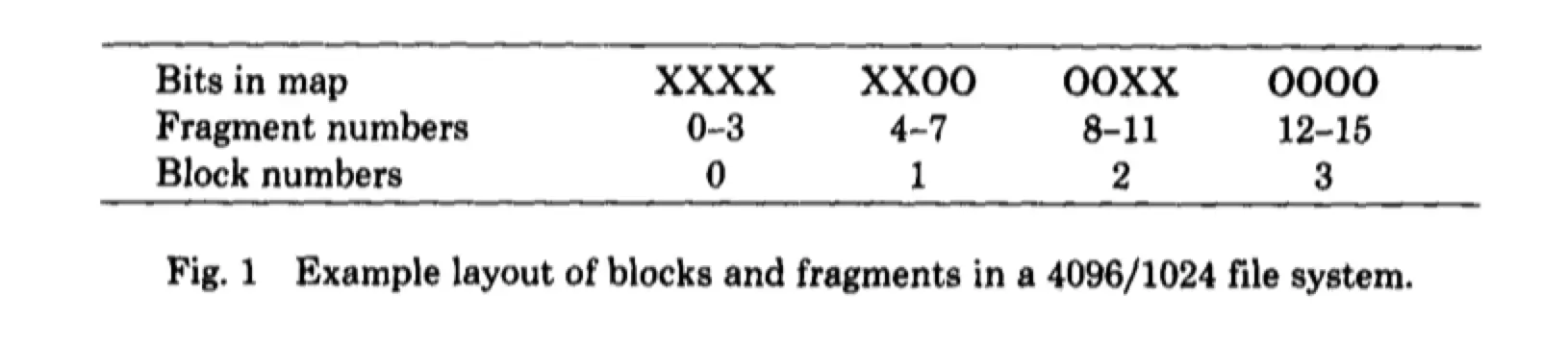
X 代表该 fragment 在使用, O 代表未使用。在这里,0-5,10,11在使用,而 6-9 和 12-15 未使用。不在同一个 block 中的 fragment 即使相邻也不能够合并为一个 block。比如 6-9 不能合并为一个 block。这里只有 12-15 才可以合并为一个 block。
假设在一个 4096/1024($BlockSize=4096Bytes,FragmentSize=1024Bytes$) 的文件系统中写入一个 11000 bytes 的文件,需要两个完整的 block 和 3 个 fragment(3 个 fragment 要求连在一起且在同一个 block 中)。如果系统中没有多余的 fragment 空间,一个新的 block 会被切分,分配掉 3 个 fragment 还剩 1 个,剩的那个可以分配给别的需要的文件。
每当系统调用 write 函数时,FFS 会检查文件是否变大(指覆盖原来的文件),是否需要扩展更多的空间来存放文件。可能存在下面三种情况:
- 在已分配的 block 中还有足够的 fragment 来存放,直接写进去就行了。
- 如果已分配文件没有空闲的 fragment(指的是已分配给这个文件的 block 中是否有空闲的 fragment) 且最后一个 block 中没有足够的空间存放新数据,一个完整的 block 会分配。它会一直分配完整的 block 直到剩余的数据小于一个 block 的大小时,它会寻找空闲的 fragment 去存放(要连续的),如果没有的话,则会将一个 block 进行切分,来进行存放。
- 如果文件有空闲的 fragment 但是不足够存放新的数据,且新数据加上原来在 fragment 中零散的数据大于一个 block ,那么会分配一个全新的 block,然后将原来 fragment 中的零散数据和新数据一起迁移到全新的 block 中。如果剩余的新数据小于一个 block,那么这些数据会存放到现成的 fragment 中或新的 block 中。
简单来说就是:文件增长的时候,FFS 会每次给他分配一个 fragment,当分配的 fragment 凑够一个 block 的时候,它会把零散的 fragment 一起移到一个 block 中做整合,然后释放掉那些零散的 fragment,这样尽可能的使文件都在一个 block 中,避免文件碎片化。
这种扩展文件空间方法的缺点是,如果每次都是新增文件一点点,则需要频繁的复制文件(从某个 fragment 复制到另一个 block 中以此降低文件的碎片化)。这种需要用户程序提供优化,比如延迟写入,先将零散的写入存在缓存中,然后汇总成一个 block size 的大小一次性写入磁盘。
关于 FFS 的空间浪费情况,4096/1024 的 FFS 和 1024 的老文件系统拥有一样的空间浪费率(因为最小单位 fragment 为 1024 bytes)。4096/512 的 FFS 则和 512 的老文件系统一样的空间浪费率。但是 FFS相比于老文件系统,它可以用更少的索引信息来存储更大的文件,而且还拥有和老文件系统一样的小文件空间。但是这些节约的空间都因为 data block bitmap 需要占用更多的空间所抵消(因为精确到 fragment 级别)。所以 FFS 的磁盘利用率和老文件系统一样,不过可以索引更大的文件和更加高效的传输。
为了高效执行文件摆放策略,我们需要一定的预留空间( free space reserve),因为 FFS 需要一部分的临时空间来移动 fragment,将零散的 fragment 汇总在同一个 block 中,以此来提高性能。
File system parameterization
传统的文件系统,在初始化时,它会忽略掉硬件上面的参数。而 FFS 则会保存磁盘的硬件参数,比如处理器性能和是否有磁盘黑科技(例如 DMA、SCSI。不过在发明 FFS 的时候,还没有那么多的磁盘黑科技)。
如图:
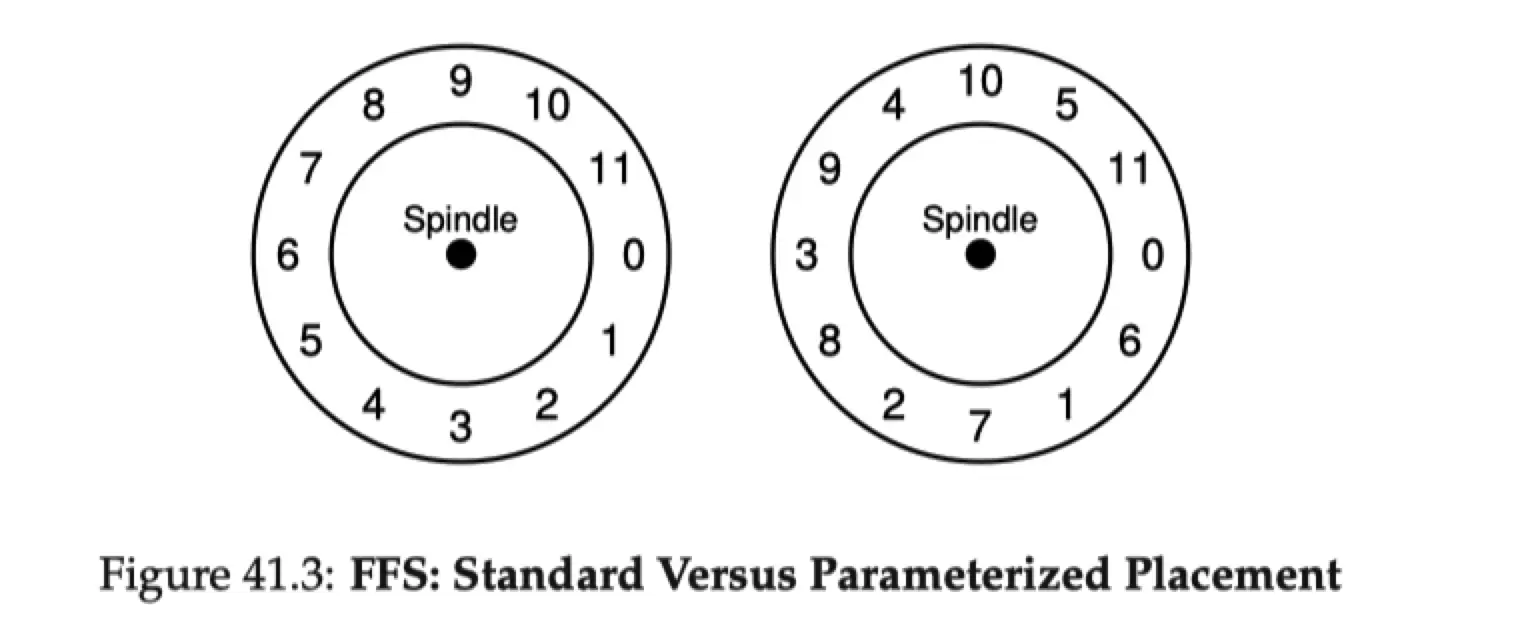
先看左边的图,没有进行任何处理的磁盘分布,每个 block 按照顺序逐个排放。假设 FFS 需要连续的读取 0 和 1 的 block。首先 FFS 读取了 block 0,但是因为 CPU 不太行,处理 block 0 耗时过长,此时磁盘的磁头已经转到 2 block 了。所以 FFS 需要等待磁头旋转一圈后才能读到 block 1。
FFS 可以根据硬件参数使用不同的布局,来解决这个问题,看右边的图,每个 block 之间都有一个间隔,这样 FFS 能够使磁头正好连续的读取 block。
Layout Policies
FFS 通过一定的文件放置策略来提升文件的 locality 来最小化读取延迟。例如 a 文件在 /dir/a,b 文件在 /dir/b,那么 a 和 b 之间的 locality 为 1。而且通常之前访问过的文件往往后面还会被再次访问。
将相关的数据尽可能的放在一起,无关的信息则尽可能分散在不同 cylinder group。比如 inode,同一个目录中的文件经常会被一起访问,例如 ls 命令,它会访问该文件夹下面的所有文件的 inode,FFS 会尽可能将这些 inodes 放在同一个 cylinder group 中。为了确保文件均匀的分布在磁盘的每一个 cylinder group 中,在创建一个新文件夹时,这个文件夹会被放在满足如下要求的 cylinder group 中(空闲 inode 数量超过平均水平,且拥有的文件夹数量最少)。在 cylinder group 内部,inode 的分配遵循(next-free strategy,就是重头开始找,找到空位就放进去)。虽然这样会使得在同一个 cylinder group 中 inode 的分布显得随机,但是磁盘其实不需要多次传输就能直接将整个 cylinder group 中所有的 inode 读取出来,因为一个 cylinder group 中的 inodes 总共就没多大,然后 block size 又是 4096 bytes,一下子就都读出来了。相比于老文件系统每次读取一个 inode 就需要一次磁盘传输快了很多。
在 data block 的分配中,当遇到大文件时,需要使用特别的手段进行处理,不然会出现一个大文件占用完整个 cylinder group 的空间,致使后续的分配都不能分配到这个 cylinder group。理想状态中,每一个 cylinder group 都不能完全填满,要留有余地。
假设我们有一个文件 a (30 blocks),我们把 FFS 配置为每个 cylinder group 10 个 inodes,40 个 data blocks,如果不作任何处理,我们放置文件 a 后效果如下:

可以看到,cylinder group 0 中所有的 data block 基本都被 a 占领了,这里没有别的空间给别的文件存储了。
所以 FFS 会把一个大文件切分为多个 chunk,然后分散在多个 cylinder group 中。例如下面,我们设置每个 chuck 为 5 个block,文件 a 存放如下:

也许你会觉得这样会影响性能,毕竟存储都不连续了。但是只要你 chunk 足够大,那么磁盘寻道的时间就会显得微不足道,比如你 chunk 为 1MB,读取出来需要 1s,而磁盘寻道时间为 100 ms,这样磁盘的寻道时间就显得微不足道。FFS chunk size 划分的比较简单,它每 4MB 划分一个 chunk,唯独的例外就是 inode 中 12 个 direct pointers 指向的 48 KB 空间划分为一个 chunk。为什么是 4MB?因为一个 block 为 4096 bytes,32 位系统中一个指针占用 4 bytes,在 indirect pointer 中,一个 block 中存放的指针可以指向 1024 个 block(共计 $1024 \times 4096Bytes=4MB$)。
现在情况变了,因为磁盘性能提升,磁盘的读取速度提升了(磁盘读取耗时降低),但是磁盘的旋转速度和磁头的速度没有显著的进步(意味着磁盘寻道速度没有加快)。也就是现在我们 chunk 需要设置的更大,因为寻道所花的时间占比更加大了。
File System Functional Enhancements
FFS 做了一些功能上的加强,这些特性都被后续的文件系统所逐渐普及。
Long File Names
支持到最大 255 长度的文件名。
File Locking
没仔细看,感觉和现代文件系统差距较大。
Symbolic Links
硬链接新建一个文件名指向同一个 inode,且在 inode 的链接数中 +1。即使删除了源文件,也不会影响新建硬链接的存在。
这里顺便说一下目录文件的”链接数”
创建目录时,默认会生成两个目录项
.和..
.的 inode 号码就是当前目录的 inode 号码,等同于当前目录的硬链接
..的 inode 号码就是当前目录的父目录的 inode 号码,等同于父目录的硬链接所以,任何一个目录的硬链接总数,总是等于2加上它的子目录总数(含隐藏目录)。
Symbolic link 只会存路径名称,不会直接指向文件的 inode。每一次访问,操作系统需要重新解析路径名称,然后获得该文件的 inode,然后再进行访问。所以当源文件被删除后,symbolic link 就会找不到文件了,不过 symbolic link 本身还会在。
Rename
不同于以前,修改一个文件名首先要新建一个临时文件,然后重命名,再删除原来的。需要 3 次系统调用,中途一旦出现中断,会使得临时文件没有被清理,变成垃圾文件。
FFS 提出 atmoic rename,防止中途断电等异常产生的中断使得文件重命名失败且残留垃圾文件。
Quotas
就是每个用户都拥有一部分空间,有一个配额限制。现代文件系统基本都支持这个功能了。
Conclusion
FFS 文件系统是文件系统历史上的一个分水岭,后面的文件系统基本都从 FFS 中汲取了一些经验。
Certainly all modern systems account for the main lesson of FFS: treat the disk like it’s a disk.