FLP 这篇论文在分布式领域有着重要的作用,当然,这篇文章也写得晦涩难懂。这是第一篇我死扣每个字读下来的分布式论文,十分吃力,在此记录下,并且竟可能写的简单,希望能够帮助初入分布式计算的新人们够更加容易理解 FLP 论文。当然再怎么简单,数学的符号是跑不了的,但是不要害怕,一个一个字看下来即可。
论文原文的名字叫:Impossibility of Distributed Consensus with One Faulty Process。简单的叫法是 FLP-Impossibility。
文章写的不是很好,感觉自己并没有深入骨髓的了解它,也许等将来的某一天,更强了,再回来重构这篇文章吧。
— 写于 2021.12.12
前言
FLP 定理相当于给分布式一致性算法订上了棺材板,它证明了根本不可能实现一个真正意义上的共识算法。
FLP 证明了在一个异步的网络环境中(没有丢包,消息不会被重复传递),最多只有一个节点发生故障,都不存在一个共识算法。可以想象如此宽松的条件下都不存在,更不用说现实环境了。
当然在开始之前,先说明一下论文所认可的真正意义上的一致性算法是怎么样的:
Validity:有效性(合法性),如果所有节点中的数据只有 0 和 1 两种,那么最后达成一致的决议一定是 0 和 1 这两种的一个。不可能说算法莫名其妙的达成一个一致的数值如 -1。
Agreement:一致性,所有节点达成一致的决议。
Termination:终止性,所有正常运行的节点最终都能够做出决议。
注意,你所知的共识算法如 Paxos 或 Raft 都不是真正意义上的一致性算法,因为它们无法同时满足上面的三个条件。
Terminology 术语
下面的术语说明只针对于本篇论文,当然你可以先跳过本节,等到后面看到相关的术语,再返回这里进行查阅。
Consensus algorithm:共识算法,也可以说是一致性算法,比如 Raft,Paxos 都可以叫 consensus algorithm。
Byzantine Generals problem:拜占庭将军问题,就是指数据在传输的过程中被篡改了怎么办。通常 consensus algorithm 都会假设不出现拜占庭将军问题,即假设了数据在传输过程中不会被篡改(节点不会收到一个被伪造过的数据)。因为通常情况下,网络协议如 TCP 就能够保证你拿到的数据大概率是对的,而且一致性算法一般运行在内网里面,相对安全。
Process:在论文中你可以把它理解为分布式系统中的一个节点。每一个 process $p$ 有一个 input register $x_p$,可以理解为输入值,只有 0,1两种。此外 process $p$ 还有一个 output register $y_b$ ,$y_b$ 的值有 b,0,1 三种 。$x_p \in {0,1},y_p \in {b,0,1}$。
Message system:把这个想象成一个网络就行了,连接了整个集群中的所有 process。整个系统中所有的 process 均共用这一个 message system,process 通过这个进行相互之间的通讯,就是互相发送 message。
Asynchronous system:异步系统。论文中对 asynchronous system 做了如下要求:(1)你不知道每一个 process 的相对处理速度,也就是你不知道哪一个 process 会先处理完。(2)Message system 中的 message 可能会延迟到达(delay,而且你不知道延迟多久,但一定会达到)。(3)整个系统中不存在公用一个同步的时钟(synchronized clock),这意味着你不能通过时间来设计算法。(4)你没有能力侦测到某一个 process 的 dead(崩溃),某一个 process 在 dead 前也不会提前通知其他 process。
Nonfaulty:无故障。
Internal state:一个 process 的 input register $x_p$,output register $y_b$,内部存储空间等等构成一个 process 的 internal state。
Configuration:一个 Configuration 包含了整个集群中所有 process 的 internal state 外加 message system。
Step:从一个 configuration 到另外一个 configuration 的过程叫 step。比如一个 process 从 message system 接收了一份数据,然后他自己改变了自己的 output register,发送了一个 message 到 message system 中,从而整个系统形成了一个新的 configuration。
Atomic step:一个原子的 step,这一步 step 包含了 process 从 message system 接收数据,本地处理,通过 message system 发送数据给别的 process 这一过程。
Decision state:达成决议的状态,比如该 process 达成了决议,确定自己的值为 0 或 1。
Initial state:所有 process 除了 input register 可以不同,其它值都是固定给死的,其中 output register $y_b=b$。
Initial configuration:所有 process 都为 initial state,而且 message system 为空。
关于 initial state,initial configuration,configuration 这里稍微说明一下。Initial configuration 并不是真的指一致性算法刚开始运行时的 configuration,而指的是每一轮开始决议前的初始 configuration。比如我们开始第一轮决议,这时候是一个 initial configuration,在决议的过程中,我们的 configuration 每经过一个 step 就会变换一次,直到所有 process 达成统一,形成一个新的 initial configuration。第二轮的时候,我们算法又要开始决议了,此时第一轮决议的结果作为第二轮的 initial configuration,以此类推。
这也是为什么 initial state 允许 process 的 input register 可以不同,因为大家的 input register 是从上一轮决议继承下来的值。
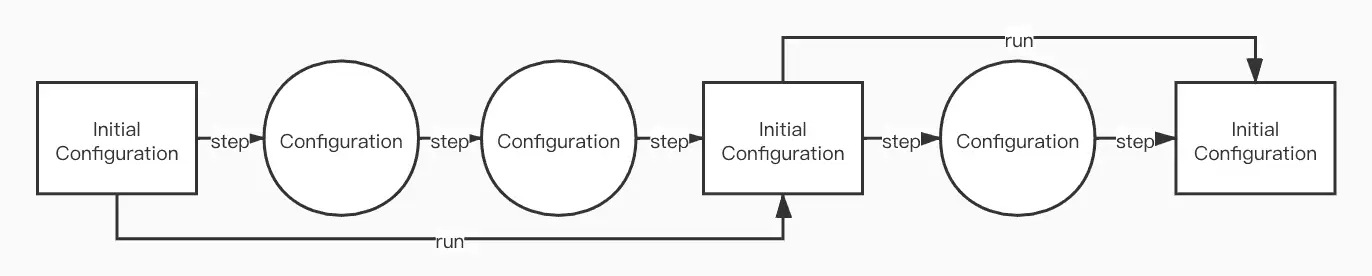

Run:一个 run 包含多个 step。
Deciding run:在这个 run 中,如果某些 process 能够到达 decision state,那么这个 run 就叫 deciding run。(注意,论文里面要求某些 process 即可)。
Admissible run:最多只有一个 process dead,其余正常的 process 都从 message system 中接收到属于它自己的 message(message system 中所有 message 发完)。
Event:$e(p,m)$ 表示 process $p$ 收到数据 $m$ 并进行处理这一过程。
Schedule:一系列的 event 组成一个 schedule。schedule 用 $\sigma$ 表示。我们用 $\sigma(C)$ 表示 configuration $C$ 通过 schedule $\sigma$ 后得到的结果。同时说明 $\sigma(C)$ 是从 $C$ reachable(可达的)。如一个 configuration 可以从某些 initial configuration reachable,那么此 configuration 是 accessible(accessible 其实和 reachable 意思差不多,只不过换个单词区分一个从 initial configuration 变的,一个从 configuration 变的)。
Accessible configuration:见 schedule 里面的说明。
Decision value:如果在一个 configuration $C$ 中,有些 process 已经处于 decision state,其输出值 $y_b=v$ ,那么我们就认为这个 configuration 的 decision value 为 $v$。注意:这里同样不需要所有 process 都处于 decision state,因为论文放宽了条件,只要一部分 process 能够做出决议,就算整体做出了决议。
注意:decision state 是针对某一个 process 的表述,而 decision value 是针对整个 configuration 的表述。
Partially correct:符合下面两个条件就可以叫 partially correct。(1)所有 no accessible configuration 都包含两个及以上的 decision value。相当于变相的说 所有 accessible configuration 都只有一个 decision value。直白的说,就是整个集群中所有 process,要么你还没处于 decision state,而处于 decision state 的 process,其达成决议的值都是一样的。(2)假设 decision value $v\in {0,1}$ 。存在一些 accessible configuration 有 decision value $v$。注意只是有些,因为有些 accessible configuration 可能还做不出 decision value。
Totally correct:在只有一个 process dead 的情况下,其是 partially correct,同时每一个 admissible run 都是 deciding run。那它就是 totally correct。
关于 partially correct 和 totally correct,这里简单说明下。你可以发现 partially correct 很宽松,只要你有做出决议的能力,十次里面有几次协商能做出决议,就算你是 partially correct。打个比方,一堆节点,开始第一轮协商,没达成,算了,然后进入第二轮。然后第二轮协商运气好,能达成决议。这样就算 partially correct。
对于 totally correct,他要求每一轮协商都能够达成协议。
这篇论文证明了,所有 consensus algorithm 在 partially correct 的情况下,存在某些 admissible run 不是 deciding run。白话说,就是任何算法都不能保证每一次协商都一定能达成决议。(这里你可以想想,如果这个算法不能保证每一次协商能够达到共识,那我们在达到共识的过程中,每一次都正好选择这个不能达到共识的过程,那不是永远都不能达到共识了。)
Bivalent:如果 configuration 中包含两个 decision value(即多个 process 中,有些 decision state 为 0,有些为 1),那就叫 bivalent。
Univalent:如果 configuration 中只有一个 decision value,那就叫 univalent。
0-valent:是 univalent,其 decision value 为 0。
1-valent:是 univalent,其 decision value 为 1。
Model
这里具体说明一下论文建立的模型。
论文假设的一个宽松的分布式环境:
- 不考虑 Byzantine failures。
- 假设 message system 是可靠的,不会丢失数据,不会给 process 重复发送数据(exactly once)。但是注意,message system 里面发送的数据可以是乱序的,即不保证数据传输的先后顺序,而且有时候会返回空( $\emptyset$)。
- 存在一个 process 会在某一个不恰当的时间 dead。
在上面这三个这么宽松的条件下,论文证明了不存在任何一个 consensus algorithm 能够保证一致性。
- 为了简化,论文假设所有 process 的 input register $x_p \in {0,1}$ 。所有 nonfaulty process 都会在进入 decision state 时决议出一个值 output register $y_p \in {0,1}$。正常来说,既然是 consensus algorithm,那肯定要保证所有 nonfaulty process 在 decision state 选择的都是同一个值,比如大家都选 0 或 1。但是论文中在此处再一次放宽条件,它只要求部分 nonfaulty process 都够做出决定,到达 decision state 就行了。
- 前面说过,message system 可能会返回 $\emptyset$ ,但是论文假设了,如果一个 process 不停的从 message system 接收 message,那它终究能够接收到本应该发给它的 message。这样就模拟了网络的延迟,但是消息一定会送达。(message system 通过发送 $\emptyset$ 的方式来模拟延迟)。
Consensus protocol $P$
假设一个共识算法 $P$,运行在一个 asynchronous system 里面,确保整个系统的 process 数量 $N\geq2$ 。每一个 process input register $x_p$只能是 ${0,1}$ 中的一个,$x_p \in {0,1}$,output register $y_{p}$ 为 ${b,0,1}$ 中的一个,$y_p \in {b,0,1}$。一个 process 处于 initial state 时,它的 output register $y_p=b$ ,$y_b$ 会通过 transition function $p$ 变为 0 或 1。当 process 做出了决议(到达 decision state),那么 transition function $p$ 就不能够再改变其 output register。可以理解成 output register 为 write-once。
关于 transition function $p$,你把他理解为一个 process 接收到了 message,调用自己的 transition function(内部函数),变更了自己的 internal state。
Process 之间的通讯通过 message system 实现。message 的格式为$(p,m)$ ,$p$ 是目标 process,$m$ 是 message 内容。整个 message system 你可以想象成一个缓冲区 buffer(不保证 message 顺序)。
Message system 支持两种操作:
- $send(p,m)$,将 $(p,m)$ 放在 message system buffer 中。
- $receive(p)$ ,从 message system 中取出属于 process $p$ 的 message。如果取出成功,那 message system 就会移除这个 message。当然也有可能取出失败,返回一个 $\emptyset$ 。
Message system 通过上面两种操作,模拟了整个分布式系统中网络的不确定性(不过至少还保证了数据不会没了,比现实生活中好多了)。
假设整个系统的 configuration 为 $C$,$e(C)$ 表示一个 event 发生在 configuration 为 $C$ 的集群上后的结果。
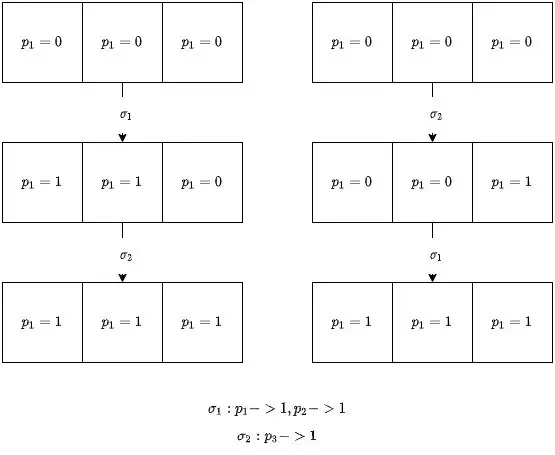
Lemma1 “Commutativity” property of schedules
Suppose that from some configuration $C$, the schedules $\sigma_1$ , $\sigma_2$ lead to configuration $C_1$, $C_2$ , respectively. If the sets of processes taking steps in $\sigma_1$ and $\sigma_2$, respectively, are disjoint, then $\sigma_2$ can be applied to $C_1$ and $\sigma_1$ can be applied to $C_2$ , and both lead to the same configuration $C_3$ 。
如下图,假设两个 schedule $\sigma_1$ 和 $\sigma_2$ 没有交集,$\sigma_1$ 只修改 $p_1,p_2$ 的值,$\sigma_2$ 只修改 $p_3$ 的值。可以看到无论先执行哪一个 $\sigma$ ,最后结果都是一样的,这就是 schedule 的交换律。
Main Result
先说结论:
No consensus protocol is totally correct in spite of one fault.
只要有一个节点故障,没有一个 consensus algorithm 能够达到 totally correct。
论文通过反证法证明,假设一个 consensus algorithm $P$ 是 total correct。反证法的 idea 分两步:(1)存在 initial configuration 是 bivalent(2)证明 consensus algorithm 从一个 bivalent intial configuration 出发,永远存在一个 admissible run 使得系统无法做出决定。
Lemma2
$P$ has a bivalent initial configuration.
为了证明,我们使用反证法,假设 $P$ 不存在 bivalent initial configuration。那么 $P$ 只存在 0-valent 或 1-valent 两种之一情况。你不可能说只存在 0-valent 和 1-valent 中的一个,因为如果这样的话,你的共识算法还有什么意义?反正大家都说好是一个值了,不需要变了。
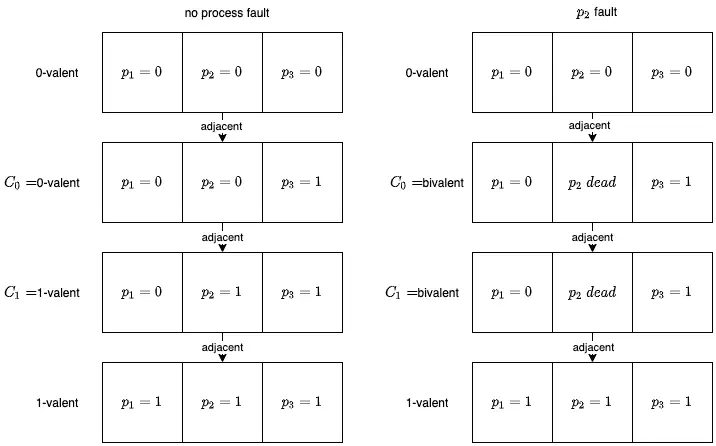
如上图,如果两个相邻的 initial configuration 只有一个 process 的值不同,那么这两个 initial configuration 叫 adjacent initial configuration。同时假设我们的 consensus algorithm 的规则为少数服从多数:$process=i$ 的 process 数量最多多,那么该 configuration 就是 i-valent。
左侧是没有节点出现故障的情况下,initial configuration 变化过程。
右侧假设 $p_2$ 在某个不恰当的时候 dead 了,此时可以注意到,其实右侧的 $C_0$ 和 $C_1$ 是一样的(去除了 $p_2$)。那么请问,它们到底是 0-valent 还是 1-valent 呢?$C_0$ 原本是 0-valent 的($P_2$ 正常运行时),但是它现在和原本是 1-valent 的 $C_1$ 一样。同理 $C_1$ 也这样。也就是说 $C_0,C_1$ 现在即可以是 0-valent 也可以是 1-valent,它根本就无法做出决议,那也就是说它们是 bivalent 的。但是我们假设的是所有 initial configuration 是 univalent 的,自相矛盾,所以 Lemma 2 正确。
Lemma3
Let $C$ be a bivalent configuration of $P$, and let $e=(p,m)$ be an event that is applicable to $C$. Let $\mathbb{C}$ be the set of configurations reachable from $C$ without applying $e$, and let $\mathbb{D}=e(\mathbb{C})={e(E)|E\in \mathbb{C}} $ and $e$ is applicable to $E$. Then, $\mathbb{D}$ contains a bivalent configuration.
同样,我们使用反证法,我们假设 $\mathbb{D}$ 不存在 bivalent configuration。每一个 configuration $D \in \mathbb{D}$ 都是 univalent。
假设 $E_i$ 为 i-valent configuration,且可从 $C$ 变化而来,$i \in {0,1}$ 。$E_i$ 存在 0,1两种可能是因为 $C$ 是 bivalent 的(Lemma2 已经证明)。存在 $F_i \in \mathbb{D}$ ,即 $F_i$ 一定是 univalent。分两种情况:(1)$e$ 发生在 $E_i$ 之后,那么 $E_i \in \mathbb{C}$, 存在 $F_i=e(E_i) \in \mathbb{D}$ 。(2)$e$ 发生在 $E_i$ 之前。存在 $F_i \in \mathbb{D}$,$F_i = e(bivalent) \in \mathbb{C}$ 变化而来。然后可以从 $F_i$ 变化成 $E_i$ 。可以看下图加深理解。
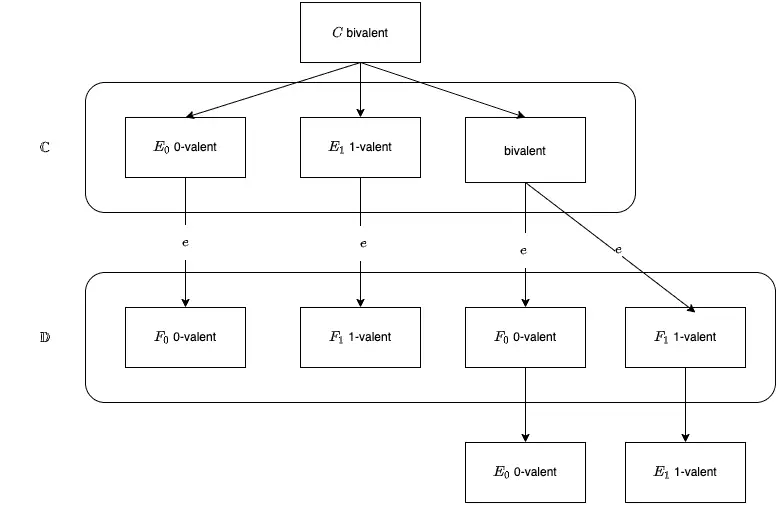
定义两个 configuration 通过一个 step 变化而来的关系叫 neighbors。
假设存在两个 neighbor 关系的 configuration $C_0, C_1 \in \mathbb{C}$ ,$C_1=e'(C_0)$ 同样存在 $D_i=e(C_i) \in \mathbb{D}$ 。注意,$D_i$ 是 univalent 的(我们之前假设的)。$e=(p,m),e’=(p’,m’)$。
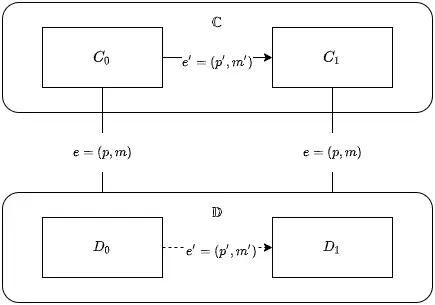
Case 1: 如果 $p’ \neq p$ ,根据 Lemma1 交换律,那么存在 $D_1=e'(D_0)$ ,因为 $e$ 和 $e’$ 没有交集,可以使用交换律。可以发现这样违背了 $D_i$ 是 univalent 的假设,你从 $D_0$ 的 0-valent 变成 $D_1$ 的 1-valent,那不是变相的说明了 $D_0$ 是 univalent 的。
注意这里 configuration 一旦变成 i-valent 了,那就代表已经做出决策,不能再变了。
Case 2: 如果 $p’=p$ ,有交集,不能用交换律了。这时我们考虑,存在一个 deciding run 从 $C_0$ 出发,在这个 deciding run 中,我们假设 $p$ 是 dead 的。
假设存在一个 deciding run $\sigma$(process $p$ dead),$A=\sigma(C_0)$ 。
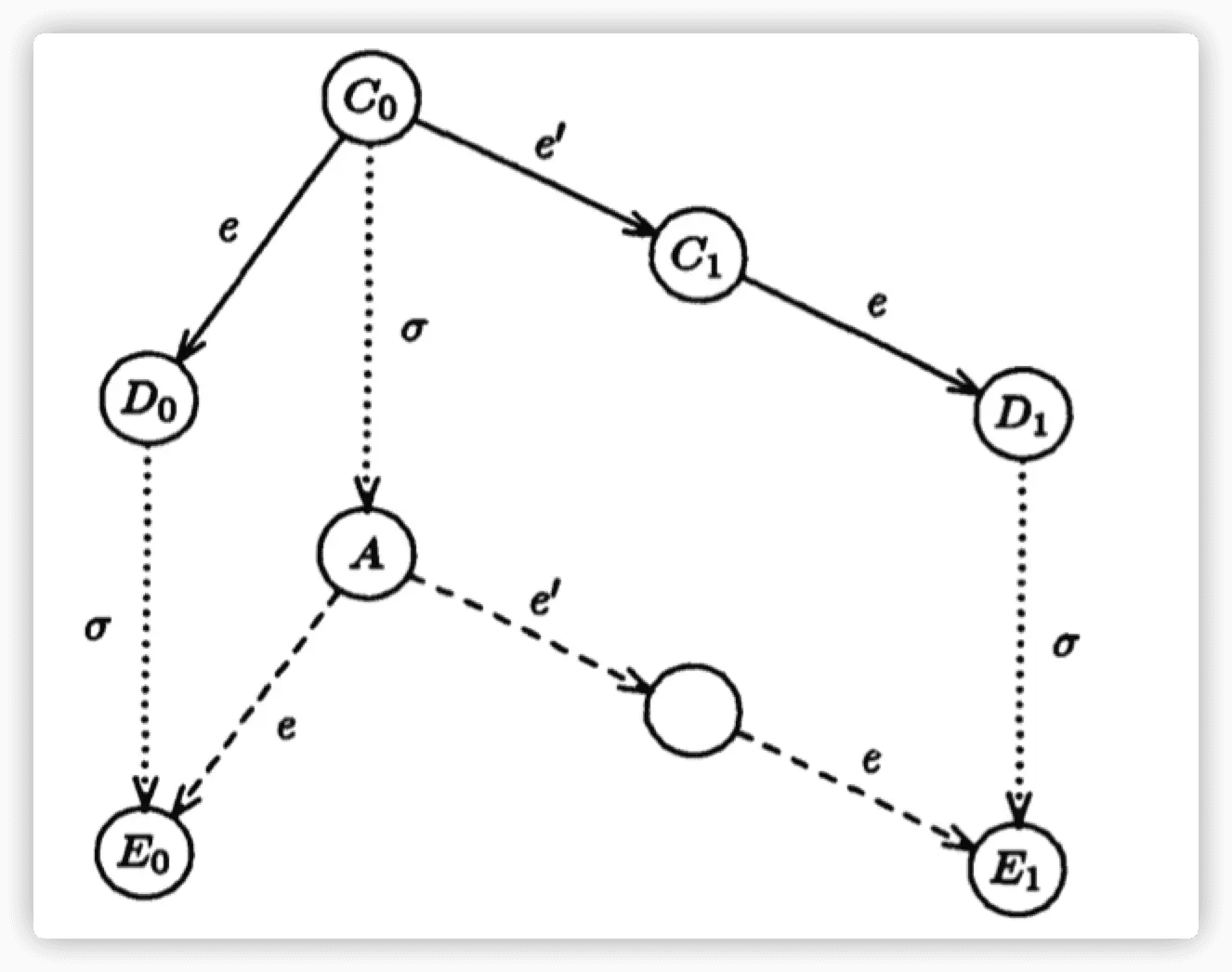
因为 $\sigma$ 里面的 $p$ 是 dead 的,那么也就和 $e,e’$ 中的 $p$ (其实是同一个 process)不会产生交集,可以继续使用交换律。
因为 $\sigma$ 是 deciding run,所以 $A$ 应该是 univalent 的。然而你可以发现,$A$ 即可以变成 $E_0$ 0-valent ,也可以变成 $E_1$ 1-valent 。这不是变相说明了 $A$ 是 bivalent 了,自相矛盾。故 Lemma 3成立。
结合
我们现在可以把 Lemma2 和 Lemma3 组合起来。根据 Lemma1,我们知道存在一个 bivalent initial configuration $C_0$ 。同样根据 Lemma 2,存在一个 event $e$ ,使得 $C_1=e(C_0)$ ,$C_1$ 是 univalent。然后你想想,如果我们每次凑巧发送这个不能做出决议的 $e$ ,那 configuration 不就是永远是 univalent 的,永远无法达到共识,即 consensus algorithm 没有 termination,也就不满足论文对真正意义的 consensus algorithm 的要求。
总结
虽然不存在真正意义的 consensus algorithm,但是人们还是想出了很多办法,来让算法变的可行。比如 Raft 和 Paxos 里面引入了随机,这样就可以一定程度上避免重复那个无法达到决议的 $e$,从而使算法满足 termination。FLP Impossibility 只是证明了一种最坏情况的存在,在实际中发的概率不会很大。当然也有些人会在 asynchronous system 的定义上面动起歪脑筋,比如在机房里面弄一个原子钟,来实现一个 synchronize clock 等等。通过理解 FLP 定理,你可以知道,分布式算法没有永恒的万能药,总是要取舍,这也为后面的 CAP 定理做了一个铺垫。
参考文献
https://www.the-paper-trail.org/post/2008-08-13-a-brief-tour-of-flp-impossibility/
http://resources.mpi-inf.mpg.de/departments/d1/teaching/ws14/ToDS/script/flp.pdf
https://www.cnblogs.com/firstdream/p/6585923.html
https://blog.csdn.net/chen77716/article/details/27963079
https://zhuanlan.zhihu.com/p/36325917
http://loopjump.com/flp_proof_note/
https://www.jianshu.com/p/33b55df03cbd
http://www.cxyzjd.com/article/bucuo12345/85006533
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/understand-flp-impossibility
 微信扫一扫
微信扫一扫
评论列表(8条)
Bivalent的定义与原论文不一致,原论文说的是所有可达配置的可能决策值
Lemma 3 第一个图没有考虑到其中一种情况,e(C)。
参见下文中的Figure 1。
https://medium.com/@li.ying.explore/understanding-of-flp-paper-impossibility-of-distributed-consensus-with-one-faulty-process-6f48b4b928d2
非常感谢!ヾ(≧∇≦*)ゝ
one crash node的在FLP证明中体现明显,那异步网络的在FLP证明中是体现在哪里呢?
@sunfish:LEMMA 3 意味着:通过延迟一条消息就可以构造出一个bivalent的配置。连续地延迟不同的消息就可以构造出一个admissible non-deciding run。
异步网络便是体现在对消息的任意延迟上,如果换成同步网络这些问题将不复存在。
Case 1 最后一句,变相说明D0是bivalent吧。
这篇论文确实不好看懂,可以加个微信交流吗
@高建国:其实细节我自己都有点忘了,说实话如果不是搞学术我感觉搞懂的意义不是很大。