数据库的事务 transaction (txn)很有搞头,特此特别记下这篇笔记,方便自己的回顾,如有错误,请指正。
Transaction
数据库事务以 Begin() 开始,以 Commit() 或 Abort() 结束。事务需要满足 ACID。
ACID
Atomicity
A:Atomicity 原子性,即多个操作合并在一起,如一个原子一样不可分割。
可以通过如下方法实现:
Logging :记录一个事务里面的所有请求到 log 中,当 abort 时,可以根据 log 日志撤销操作。每一次在 Log 中新增操作时需同时持久化到硬盘中。
Shadow Paging:修改数据时,拷贝一份该数据的 page,在其上面修改。当该事务 commit 之后,该 page 才对其他事务可见。
Consistency
C:Consistency,一致性,这个和分布式系统的里面的一致性含义并不相同。CAP 中的一致性更多指的是数个副本的一致。ACID 中的一致性指的是数据库处于应用程序所期待的状态。比如银行从 A 账户转一部分钱到 B 账户,肯定是希望 A+B 账户的总金额在任何时刻都是一样的。
Isolation
I:Isolation,独立性,即不同的事务之间不会互相干扰,互相独立。
数据库通过 concurrency control(并发控制)来保证不同事务之间的独立性,互不干扰。并发控制分为乐观模型和悲观模型。
Optimistic:假设事物的冲突是很少发生的,只有当事务 commit 的时候,才会检查是否存在冲突,确实是否需要 abort。适合多读少写的场景。通常基于 MVCC,timestamp 的并发控制是乐观模型。
Pessimistic:假设冲突是经常发生,在一个事务开启的时候,就先检查是否存在冲突。适合少读多写的场景。通常基于锁的的并发控制是悲观模型。
Durability
D:Durability,就是持久化。同样可以通过 logging 或 shadow page 来实现。
Schedule
Schedule 顾名思义就是多个 txn 怎么个安排法。
Serial Schedule
指的是多个不同事务按顺序执行。如下图先执行 后再执行 ,或先执行 再执行 ,两个 txn 不会穿插在一起。
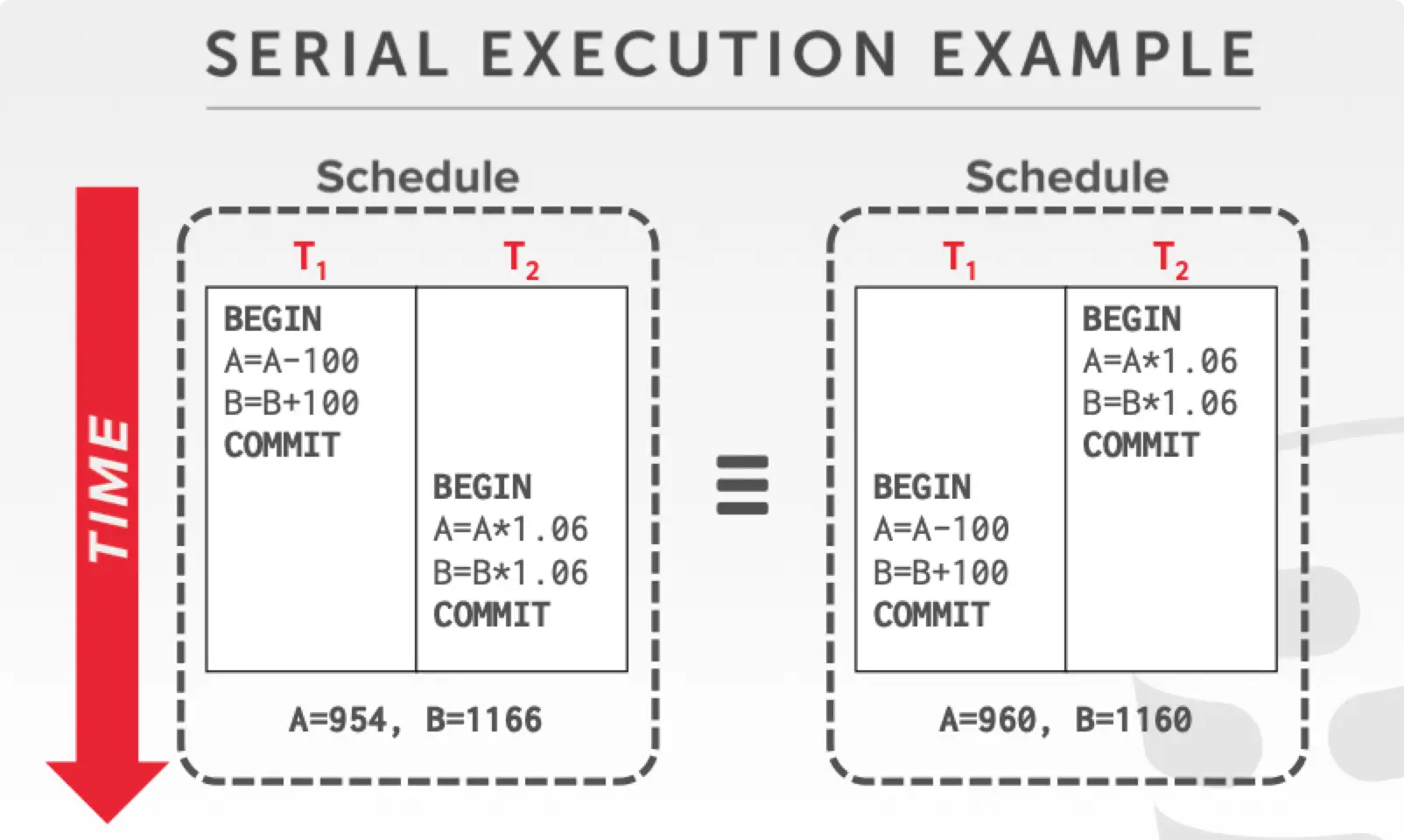
如果数据库种所有的 schedule 都是 serial schedule,这样性能很差,相当于数据库是单线程执行的(不过 Redis 好像就是单线程)。数据库并发控制存在的意义就是让并发执行的 schedule 的结果和你 serial schedule 执行的结果一样。
Equivalent Schedule
在任何数据库状态下,如果两个 schedule 执行后均能得到相同的结果,那么称这两个 schedule 为 equivalent schedule。
Serializable Schedule
如果一个 schedule 和一个 serial schedule 互为 equivalent schedule,那么称该 schedule 为 serializable schedule。
Recoverable Schedule
如下是一个 unrecoverable schedule 的例子:
| read(A) | |
| write(A) | |
| read(A) | |
| commit() | |
| abort() |
读取了 未 commit 的 A 并自己完成了 commit,此时如果 之后选择了 abort,为保证事务的原子性,按理 也需要撤销,但是 已经是 commit 了,无法撤销,所以是 unrecoverable schedule。
如果想让上面的例子变为一个 recoverable schedule,只需要保证 在 commit 时进行阻塞,直到 结束后再执行。
Cascadeless Schedule
如下是一个 cascade schedule 的例子:
| read(A) | ||
| read(B) | ||
| write(A) | ||
| read(A) | ||
| write(A) | ||
| read(A) | ||
| abort() |
在上面的例子中, 和 均读取了未 commit 的 A,如果 abort 后,为保证原子性, 和 就需要 cascading rollback,这导致大量已执行的事务被浪费。
解决办法很简单,在 和 read(A) 时进行阻塞,直到 commit 或 abort 后才开始执行。这样的 schedule 就叫 cascadeless schedule。
很好理解 cascadeless schedule 必定是 recoverable schedule。
Serializable
Conflict
假设 和 两个 txn,两个事务均包含共同的 item 操作。
- 如果 和 均执行 ,则无论先后顺序,执行结果都一样。
- 如果 和 一个执行 ,一个执行 ,则不同的先后顺序结果会不一样。这就产生 conflict,也叫 read-write conflict。
- 如果 和 均执行 ,则不同的先后顺序结果会不一样。这也产生 conflict,叫 write-write conflict。
可以看出,冲突主要产生的原因是读写冲突,写写冲突。不含读读冲突。
Conflict equivalent
如果两个 schedule,在会产生冲突的操作上保持一样的顺序(其他不冲突的操作可以任意顺序),则称两个 schedule 是 conflict equivalent。
如下图,两个 schedule 冲突的顺序均为:A 的 read-write conflict -> B 的 read-write conflict。故这两个事务是 conflict equivalent 的。
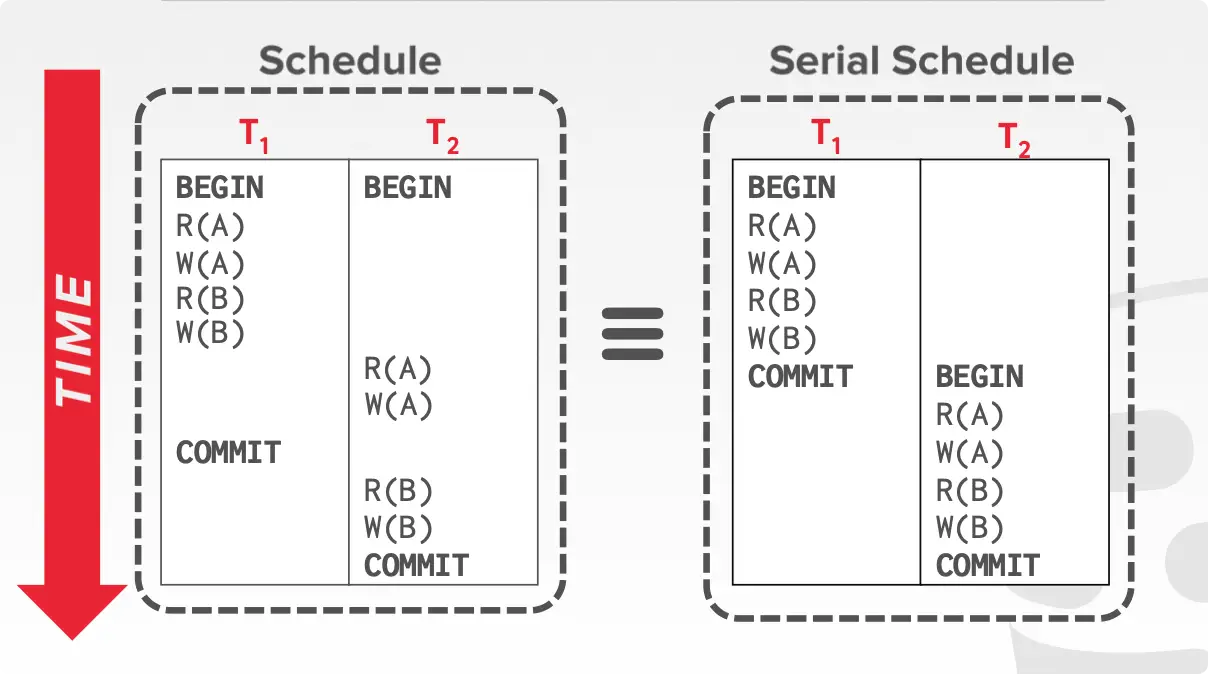
Conflict Serializable
如果一个 schedule 和 serial schedule 是 conflict equivalent 的,那么称该 schedule 是 conflict serializable。上面这个图其实也是 conflict serializable 的例子。
View Serializable
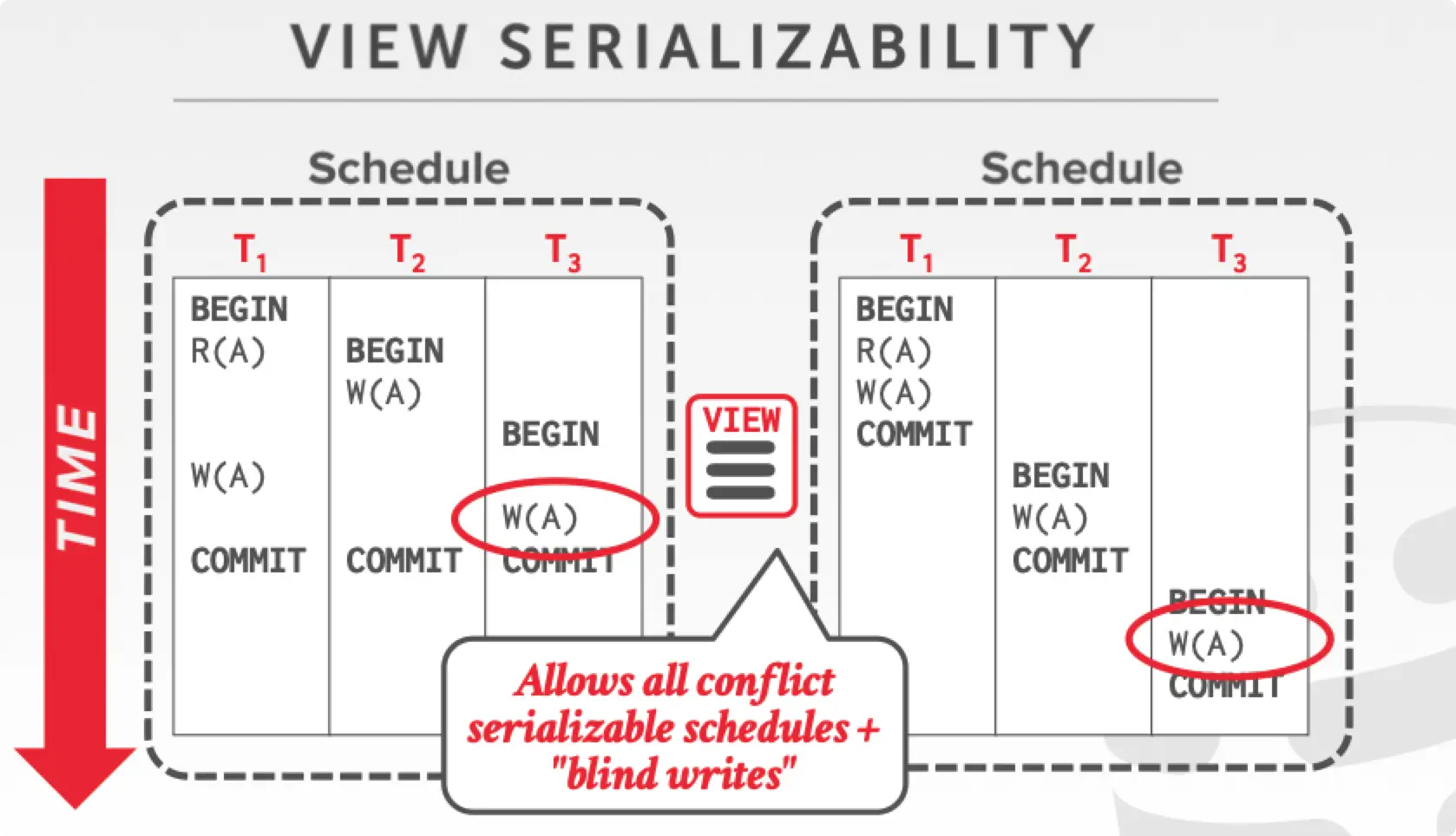
一个 schedule 最后执行的结果和 serial schedule 一样,就叫它 view serializable。如上图这种 schedule,其肯定不属于任何 conflict serializable schedule,但是其最后结果和 serial schedule 一样,故其是 view serializable。
显然可知,conflict serializable 肯定是符合 view serializable,故其属于 view serializable 的子集。
数据库很难是 view serializable 但不是 conflict serializable 的 schedule 转换为 serial schedule,因为这需要数据库能理解 SQL 语句意义才能实现这个操作。
Concurrency Control
为了实现系统的 isolation,数据库引入了 concurrency control(并发控制)。
并发控制主要基于 lock 和 timestamp 两种实现。我个人觉得 MVCC 属于 timestamp 的一种。
Lock Protocol
基于 Lock 的并发控制通常是悲观事务模型。
在数据库中,Lock 和 Latch 的说法不同,Lock 用于实现事务不同隔离级别,而 Latch 指的是我们传统多线程编程里面的锁。
S 指 Shared Lock,X 指 Exclusive Lock。
兼容矩阵:
| Shared | Exclusive | |
|---|---|---|
| Shared | true | false |
| Exclusive | false | false |
Two Phase Lock(2PL)
注意 Two phase lock(2PL) 和 Two phase commit(2PC) 是两个东西,完全不同。2PC 是分布式上面用的。
2PL 能够保证事务的 serializable,也就是实现 repeatable read。因为当你在 shrinking 阶段尝试读之前的数据,如果 lock 还在,那么肯定不会被别的事务修改;如果 lock 已经被你释放,你读取之前需要先获取 lock,但是这样就直接违反了 2PL 的规则。故其能保证 repeatable read。
注意这里的 RR 不是我们传统隔离级别的 RR。传统的 RR 是不会有脏读的,但是这里我指的 RR,存粹就只是 RR,普通的 2PL 是会产生脏读的,后面有图片例子。
2PL 将整个事务划分为两个阶段:
- Growing Phase:只获得锁。
- Shrink Phase:只释放锁。
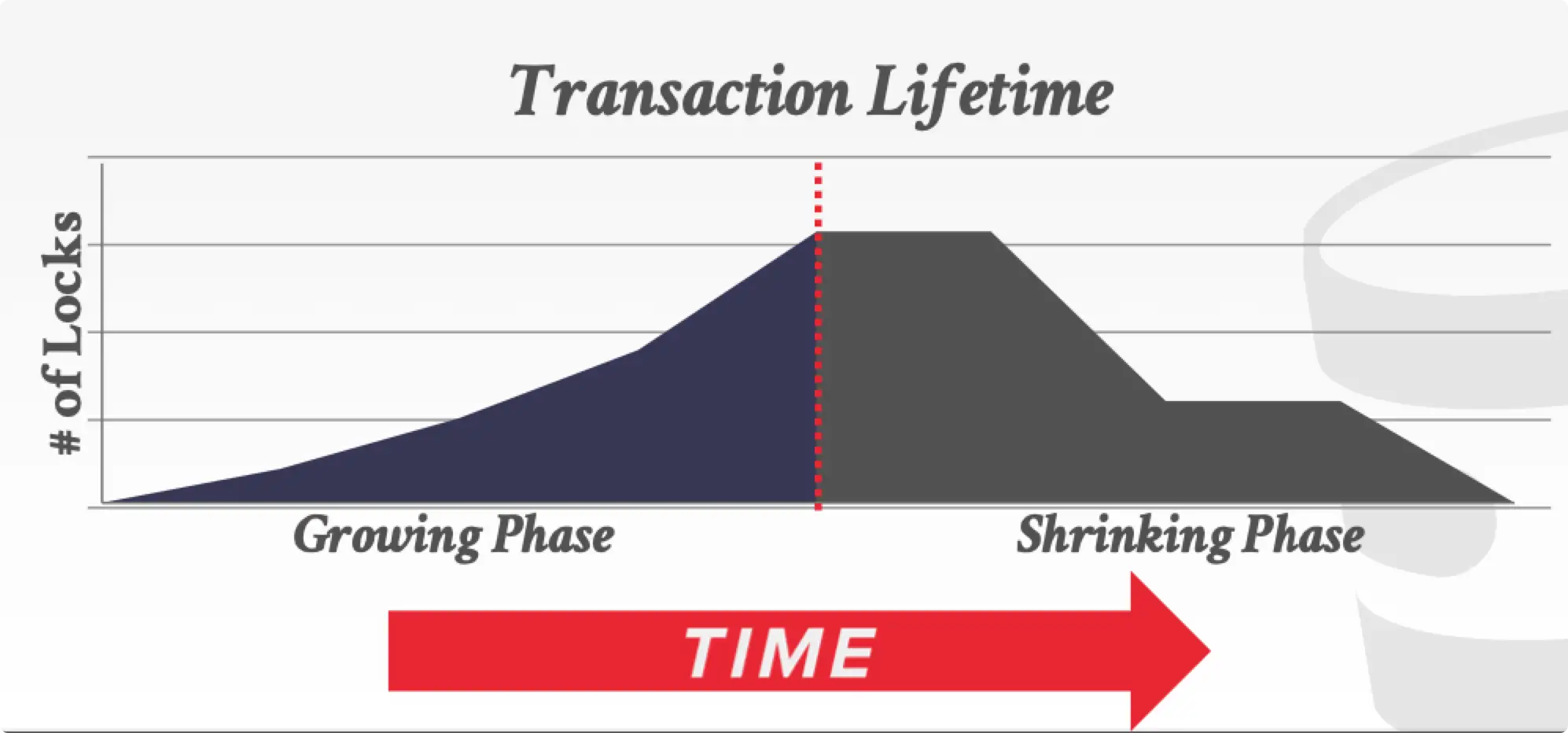
但是这样的 2PL 会产生脏读和 cascading rollback(正因为产生了脏读,才会产生 cascading rollback)。
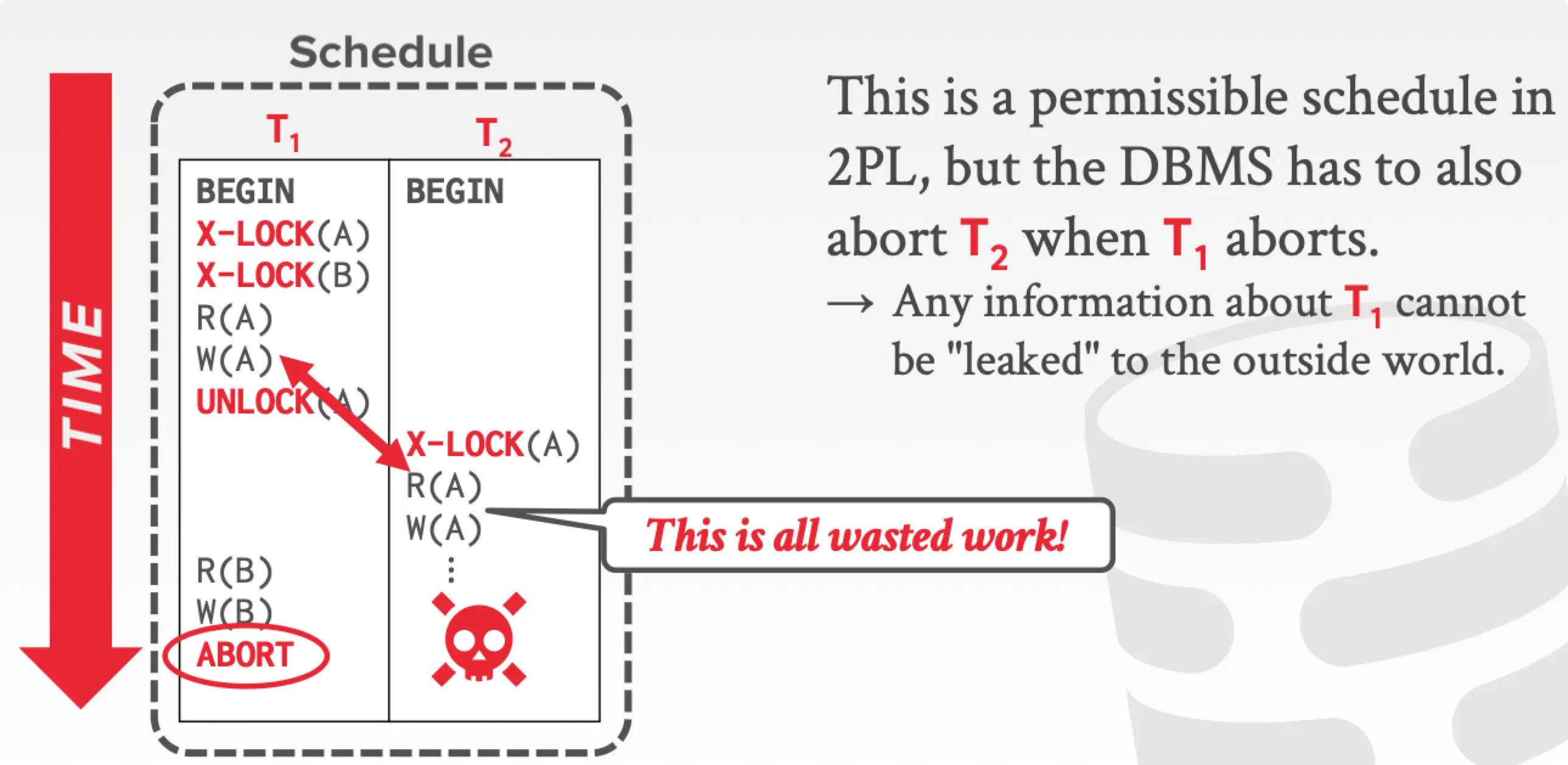
上图产生 cascading rollback 的原因是 脏读了 未提交的数据。
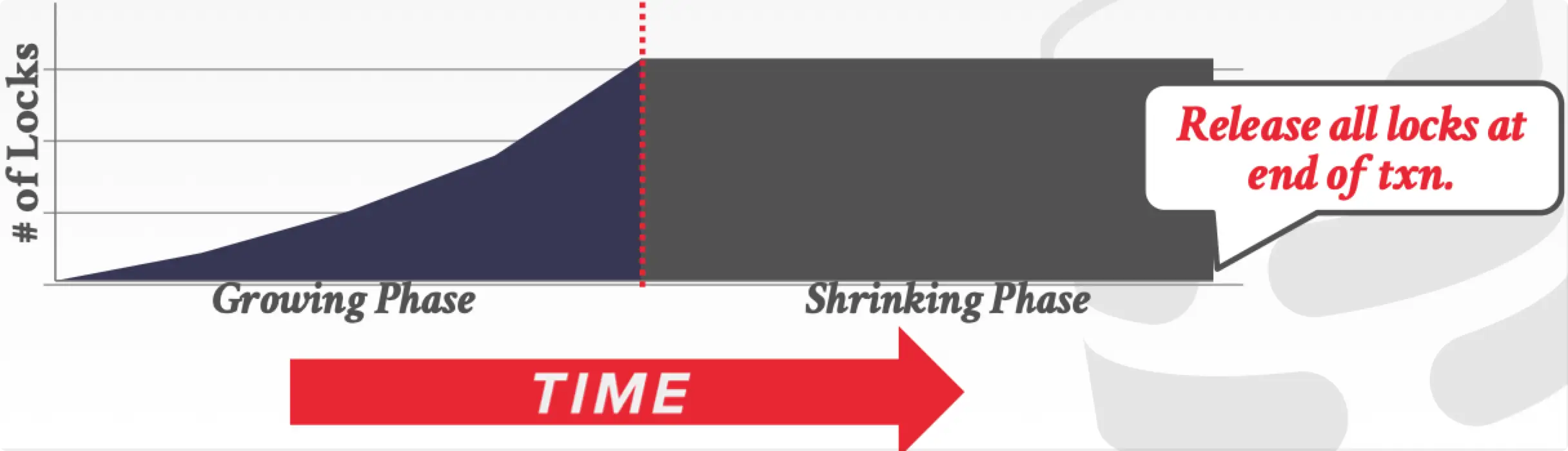
Strong Strict 2PL(aka Rigorous 2PL)
Rigorous 2PL 可以解决普通 2PL 会产生脏读和 cascading rollback 的问题。
Rigorous 2PL 规定在 Shrinking Phase 阶段,只有到 commit 或 abort 时才会一次性释放全部锁。
DeadLock
根据死锁的八股,解决死锁分为四个手段:
- 死锁避免,通过破坏死锁产生的4个必要条件,使其永远不会产生死锁。(不现实,那还要锁干啥)
- 死锁预防,在执行操作的时候检查资源,比如银行家算法,确保这个请求不会产生死锁。
- 死锁检测与恢复,允许程序进入死锁状态,然后检测是否有死锁(用图判断有没有环即可),然后进行恢复操作。
- 鸵鸟策略,不管。(不现实)
DeadLock Detection and Recovery
通过 waits-for graph 判断事务是否存在环,如果存在环则说明存在死锁,尝试恢复。数据库会选择一个 victim txn,对其进行 abort 或 restart 来打破环。
Waits-for graph 就是根据 conflict operation 画个图罢了,通常使用深度遍历判断或拓扑排序判断是否存在环。
选择 victim txn 时可以根据多种条件选择代价最小的 txn:
- Txn 的 age,最早创建的 txn。
- Txn 的 progress,执行最少 operations 的 txn。
- Txn 锁住的 item 数量。
- Txn 被 rollback 的次数。
- …自己想。
DeadLock Prevention
死锁预防,避免事务进入死锁状态。这种方法就不需要 waits-for graph。
首先规定越早创建的事务具有更高的优先级。 。事务执行时采用如下两种解决策略之一:
Wait-Die(Old Waits for Young)
- 如果请求的事务比占有锁的事务具有更高的优先级,则等待其完成。
- 如果请求的事务的优先级比占有锁的事务低,则自己 abort。
Wound-Wait(Young Waits for Old)
- 如果请求的事务比占有锁的事务具有更高的优先级,则 abort 掉持有锁的事务,自己上位。
- 如果请求的事务的优先级比占有锁的事务低,则等待。
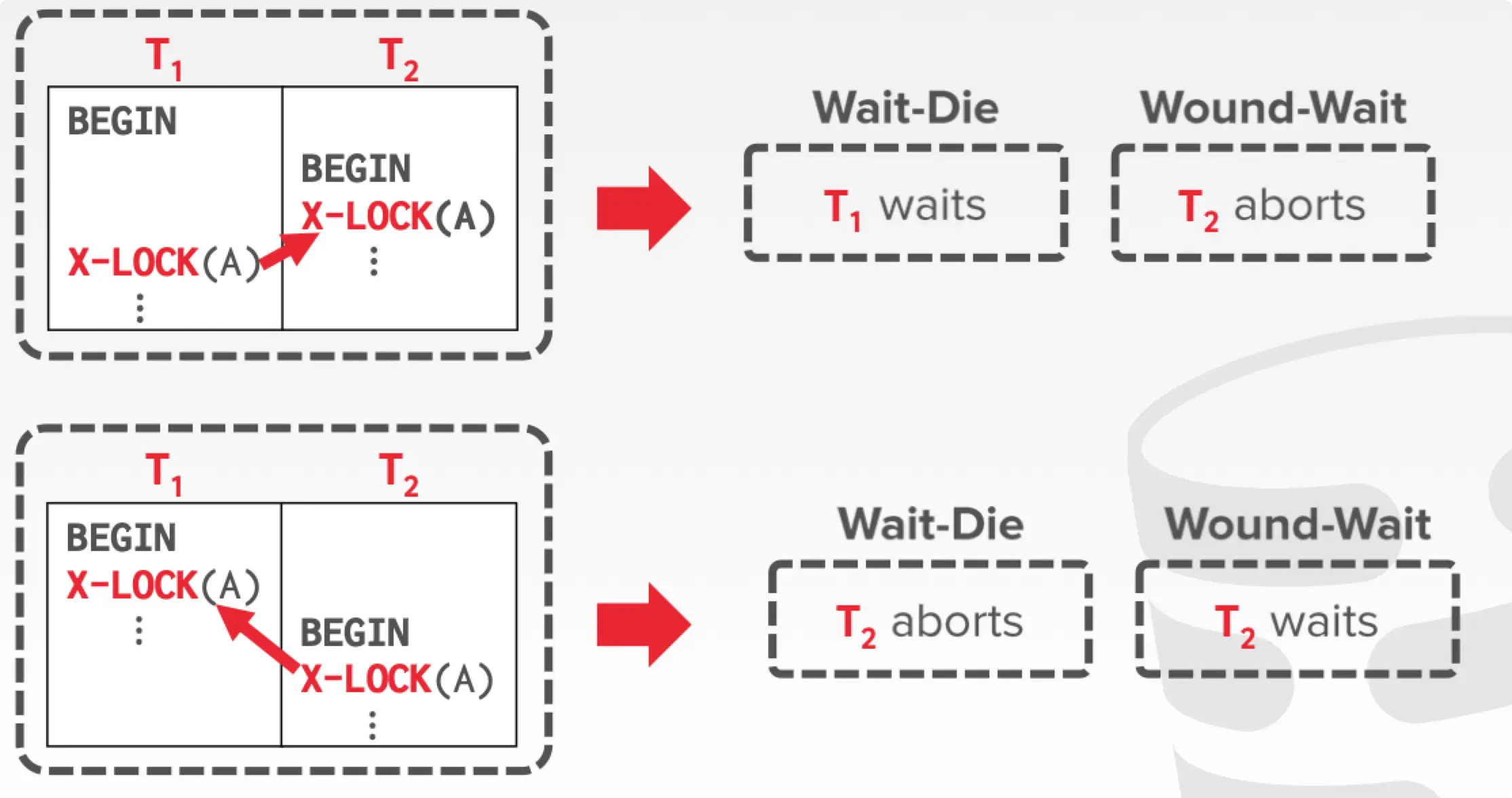
当一个 txn 被 abort 后 restart 时,需保持原有的 priority(也就是时间戳),不然它和直接新加入的 txn 有什么区别,有可能永远无法被执行。通过上述两种方法,可以保证数据库不会进入死锁状态。有那么点 timestamp-based 內味。
Multiple Granularity
在数据库中,我们不可能一个一个 item 上锁,比如执行 SELECT * FROM demo FOR UPDATE; ,不可能给 demo 中所有的 items 上锁,这不仅需要耗费大量的时间,同时 LockManager 里面也需要耗费大量内存管理 lock。我们完全可以用一个锁来表示整个 table。
所以数据库通常采用了树状的锁管理结构。
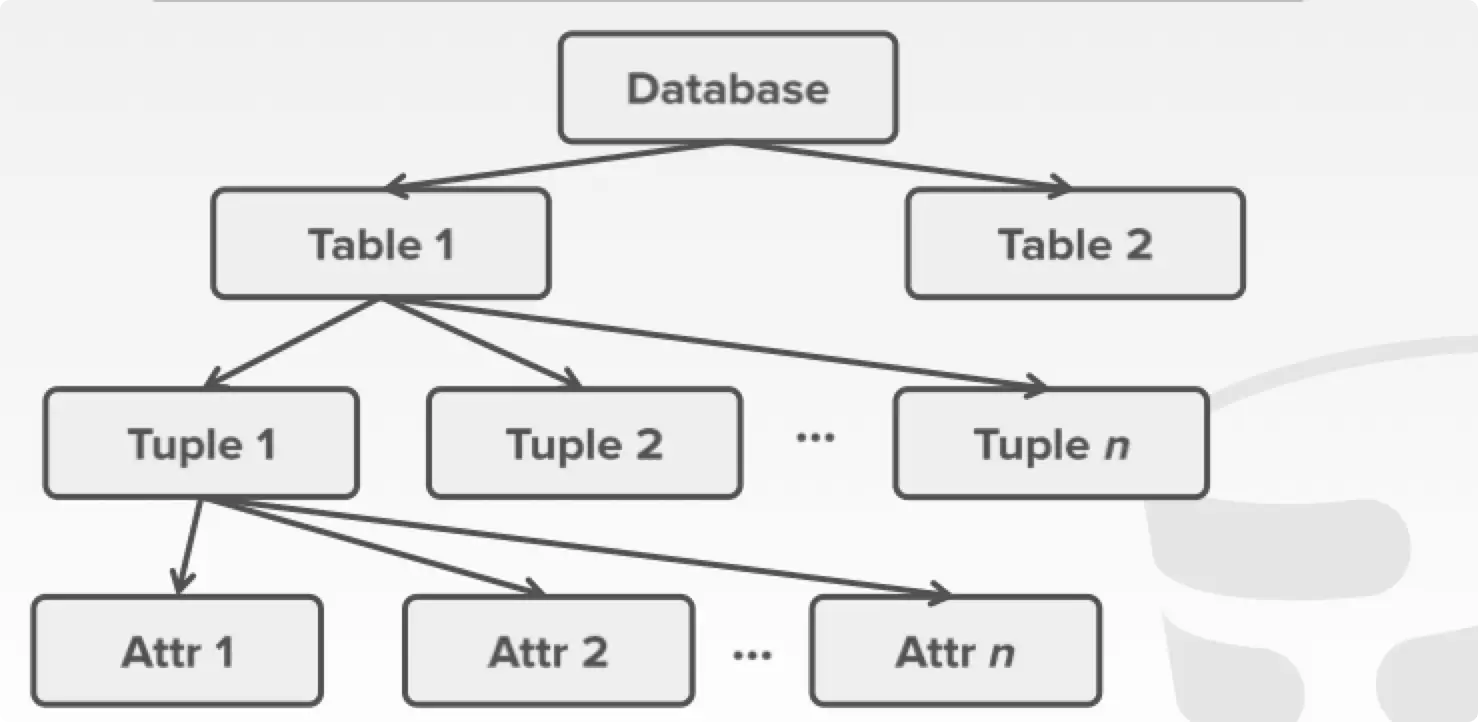
但是我们要考虑一种情况,假设 在 Attr 1 上面有 X 锁,此时 需要遍历整一个数据库,也就是在 Database 上面上 S 锁。那么 需要先遍历整个树,来判断是否存在和它冲突的锁,这会耗费大量的时间。因此引入 intention lock 来解决这个问题,intention lock 相当于在一个被操作节点的所有父节点上添加了一些额外信息,帮助其他事务不需要遍历整个 lock 树来判断是否存在冲突锁。
每一个节点上都可以加锁(Database,Table 等等均可),且一个节点上只要不冲突可以同时加多个锁。
Intention Lock 分为如下三种:
- Intention-Shared(IS):表示该节点下的子节点存在 S。
- Intention-Exclusive(IX):表示该节点下的子节点存在 X。
- Shared+Intention-Exclusive(SIX):表示该节点被加了 S,且其下面子节点存在 X。
加锁规则:
- 每一个 txn 获得锁的顺序都是从上到下,释放锁的顺序是从下到上。
- 一个节点获得 S 或 IS 时,其所有父节点获得 IS。
- 一个节点获得 X 或 IX 或 SIX 时,其所有父节点获得 IX。
例如一个事务要修改上图 Attr 1 的数据,先在 Database 上 IX 锁,在 Table 1,Tuple 1 逐个上 IX 锁,最后在 Attr 1 上 X 锁。
下图是两个事务同时上锁的效果:
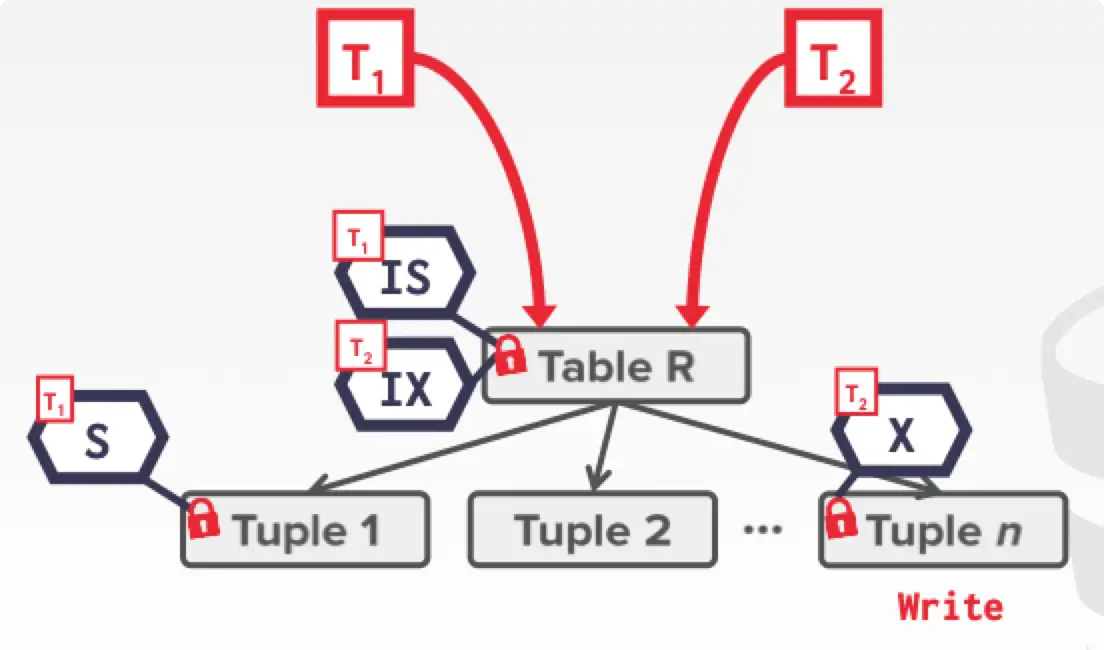
Intention Lock Compatibility Matrix
Intention Lock 的兼容矩阵如下:
| IS | IX | S | SIX | X | |
|---|---|---|---|---|---|
| IS | true | true | true | true | false |
| IX | true | true | false | false | false |
| S | true | false | true | false | false |
| SIX | true | false | false | false | false |
| X | false | false | false | false | false |
这里以下图为例子讲解几个情况:
IS-IX 兼容:假设 Attr 1 是 S,Attr 2 是 X,那么 tuple 就是 IS + IX,这是合理的,两个 txn 操作不同的 tuple,不冲突。
IS-SIX 兼容:假设 在 Attr 1 是 S,那么 Tuple 1 是 IS。假设 修改了 Attr 2 后需要遍历整个 tuple 1,故其在 Attr 2 上是 X,按道理其需要在 Tuple1 上 IX,但是因为其还需要遍历整个 Tuple1,故还要一个 S,S 和 IX 一结合,就变成了 SIX。这样也是不冲突的。
IS-X 不兼容:假设 读取 Attr 1 ,在 Attr 1 上 S,Tuple1 上 IS。此时 要修改整个 tuple1,在 tuple1 上想上 X,显然不行,因为 还在读取,故冲突。
其他例子自己推导。
Timestamp Ordering (T/O)
我们还可以采用基于时间戳的事务模型,在每一个事务开始的时候,就给它分配一个时间戳,通过时间戳在一个事务开始前就决定了其执行顺序。基于 T/0 的事务通常是乐观事务模型。
当 时,意味着 的执行顺序应在 之前。
事务分配时间戳 TS 有如下三种方式:
- System Clock,系统时间,在单机下基本没问题(分布式不可行,存在 clock drift),而且如果并发量很大,可能会将同一个时间戳分配给多个 txn。
- Logical Counter,逻辑时间,比如自增 ID,能保证每一个 txn 有一个唯一的时间戳,但是和现实时间割裂。
- Hybrid,混合时间,系统时间+逻辑时间。类似于 TiKV 里面的设计,前几位是系统时间,后几位是逻辑时间。既保证每一个 txn 有唯一的,也保证时间不会和现实时间割裂。
Basic T/O
每一个 item 拥有两个时间戳:
- W-TS(X),item X 上最新的一次写入时间。
- R-TS(X),item X 上最新的一次读取时间。
Txn 在执行每一次操作的时候,都需要检查时间戳,判断自己是不是在访问一个“来自未来”的数据,如果是,则 abort 并 restart。
每一次的 restart 都需要新分配一个时间戳。
表示 被创建时分配的时间戳。
Read Rule
如果 ,说明自己在访问一个已经被修改过的 item,abort 并 restart。
否则正常读取 X,并设置 。同时拷贝一份 X 的值在 事务中,用于保证 Repeatable Read。
使用 max() 函数原因是,item X 可能已经被比 大的事务读取过了,但是因为都是读取,就不会产生冲突。但是在写入读记录的时候你不能覆盖掉它。
Writes Rule
如果 或 ,则 abort 并 restart 。说明 item X 已经被“来自未来”的数据读取或写入过了。
否则允许 修改 X 并更新 。 同时拷贝一份 X 的值在 事务中,用于保证 Repeatable Read。
Thomas’ Write Rule
考虑下图的可能:
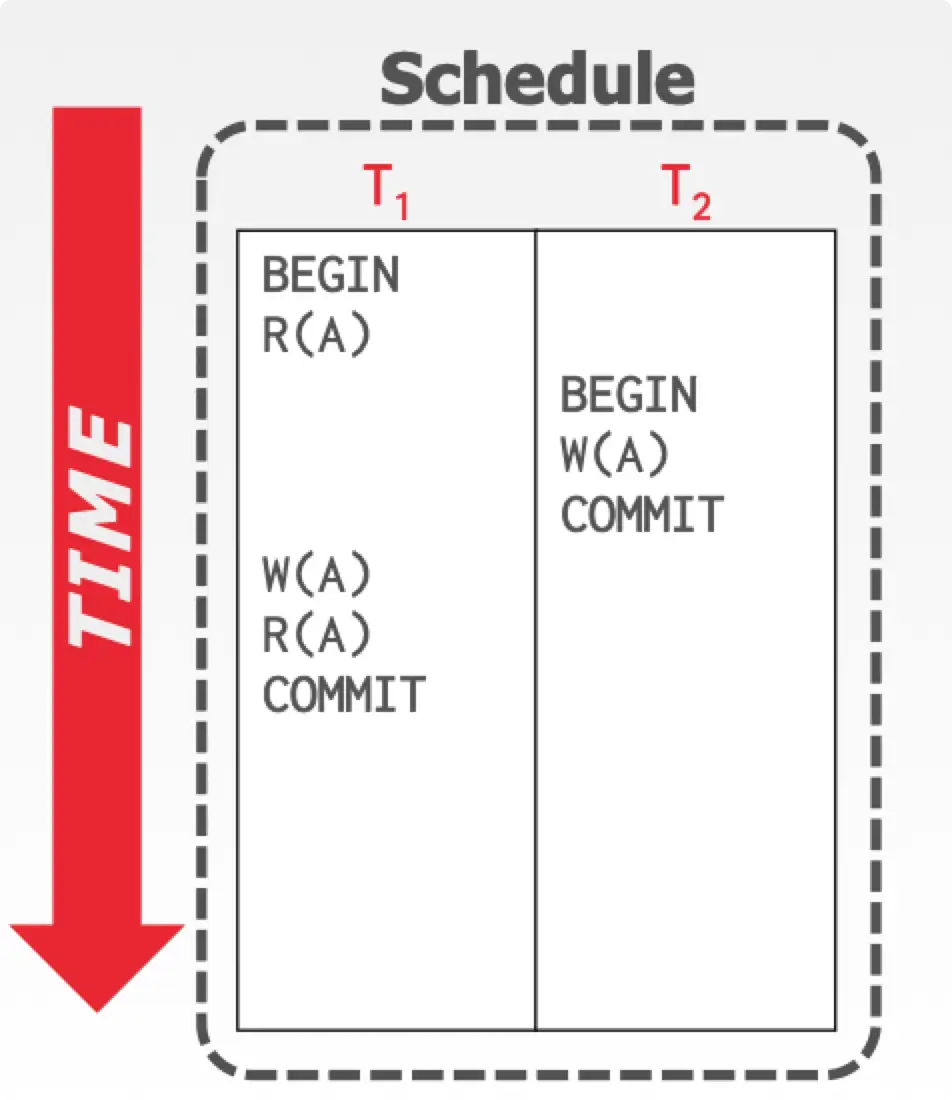
如果按照常规的 Basic T/O 模型, 在 W(A) 的时候因其违反了 ,按理需要被 abort 并 restart。但是如果我们选择忽略 的 W(A),那么 也是可以正常执行。
这里有一点奇怪,我个人觉得应该是保证 view serializablity 的前提下,才可以忽略。在 中忽略了 W(A) 操作会造成程序不符合用户的预期行为。不过这样并不会造成数据库不一致的问题,仍能够满足 ACID 中的 consistency。
Thomas’ write rule 具体规则如下,在写入时:
如果 ,则 abort 并 restart 。
如果 ,忽略当前的 write 请求。
否则就按 Basic T/O 的常规操作,允许 修改 X 并更新 。 同时拷贝一份 X 的值在 事务中,用于保证 Repeatable Read。
Basic T/O 小结
如果你不使用 Thomas’ Write Rule,基于 Basic T/O 生成的 schedule 是 conflict schedule 的。
能够避免死锁的产生,因为事务不会等待,要么成功,要么就直接 abort 并 restart。(它都没用到锁,当然不会死锁)。
存在一个长事务被连续不断到来的短事务 starve 的可能。
每一个事务都需要独立拷贝数据到自己独立空间,会带来一定的负担。
存在产生 unrecoverable schedule 的可能,如下图:
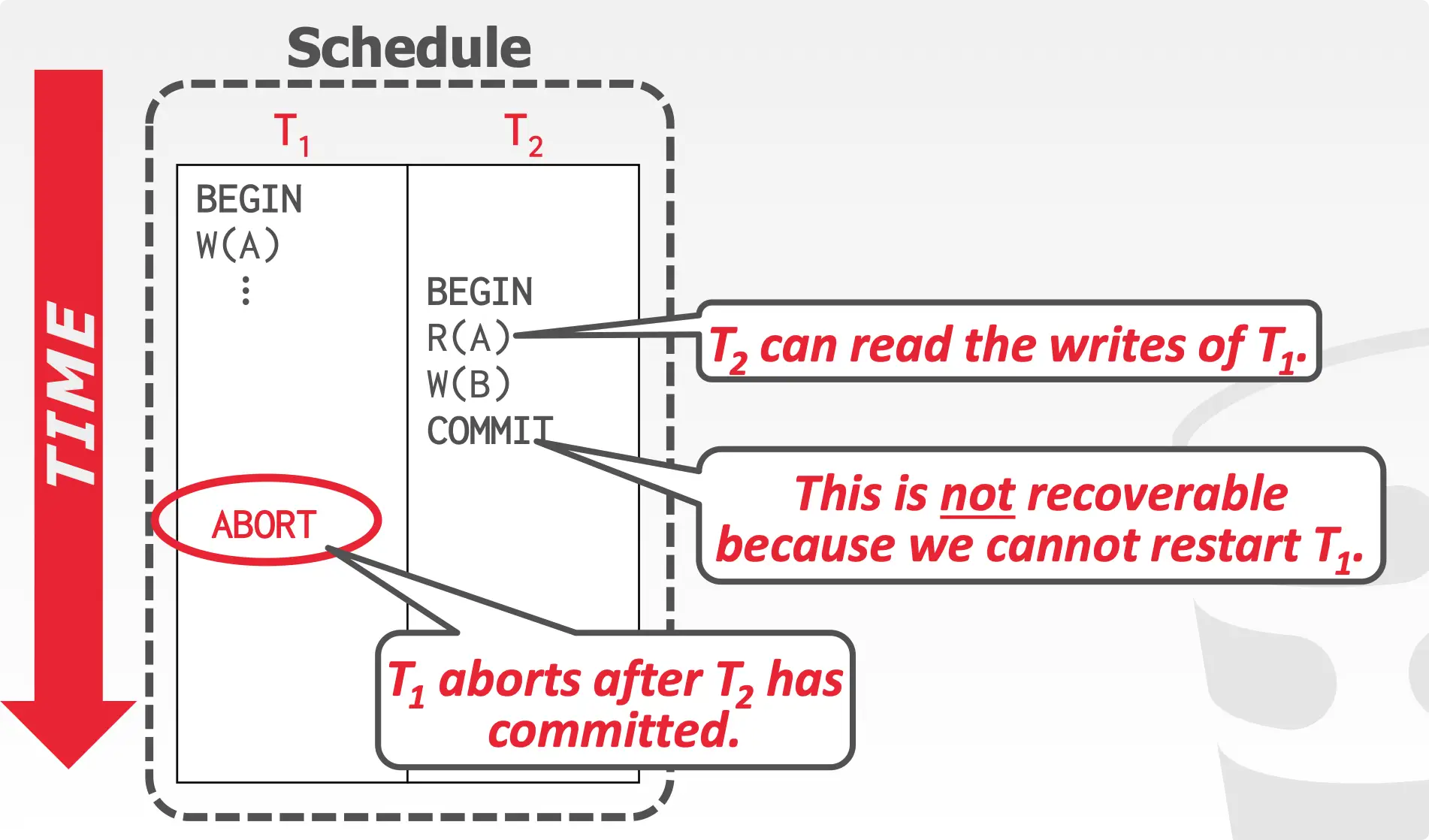
脏读了未提交的 A,并自己 commit 了,这虽然符合 Basic T/O 的规则,但是也产生了 unrecoverable schedule,不满足 ACID 中的 Atomicity。
实际上没有数据库会采用 Basic T/O 的方式来实现乐观的并发控制。
Validation-Based Protocol
事实上可以基于 Basic T/O 的规则进行改进,没必要在每一步操作的时候都判断是否需要 abort 并 restart。完全可以等到事务准备 commit 时统一判断。
当然使用这种方法的前提是大多数的事务是短事务的,而且很少会引起冲突。不然你想想一个长事务,要全部执行完才会发现冲突,结果前面都白执行,血亏。
Validation-Based Protocol 规定每一个事务有一个独立空间,读取的变量都会拷贝到这个独立空间中,修改也是在这个独立空间中修改。只有当 commit 时,才会统一检查自己空间中的数据和数据库中的数据是否存在冲突。
可以分三个阶段:
1. Read Phase
定义 为事务 的开始时间戳。
读取数据保存在当前事务的独立空间里,修改也是在该空间中进行。
2. Validation Phase
定义 为 结束 read phase 并开始 validation phase 的时间。
当事务 commit 时,检查其独立空间中的值是否会和数据库里的冲突。判断是否需要 abort 并 restart。
检查规则见后面。
3. Write Phase
定义 为 结束 write phase 的时间。
如果 validation phase 检查成功,执行 write phase,把自己空间里的值写入数据库。
Read-only 事务不存在 write phase。
小结
Read phase 没什么好说的,你所能读取到数据一定是已经被 commit 的。同时因为你不会产生脏读,所以你也不会有 cascading rollback。
决定一个事务是否需要 abort 取决于 validation phase 的结果,遵循如下两个约束:
假设存在一个事务 早于 创建 ,即 。
- 满足 ,即 早于 之前完成了 write phase。
- 不存在 的情况,也就是不存在 的 write phase 穿插在 执行的过程中。
例子如下图:
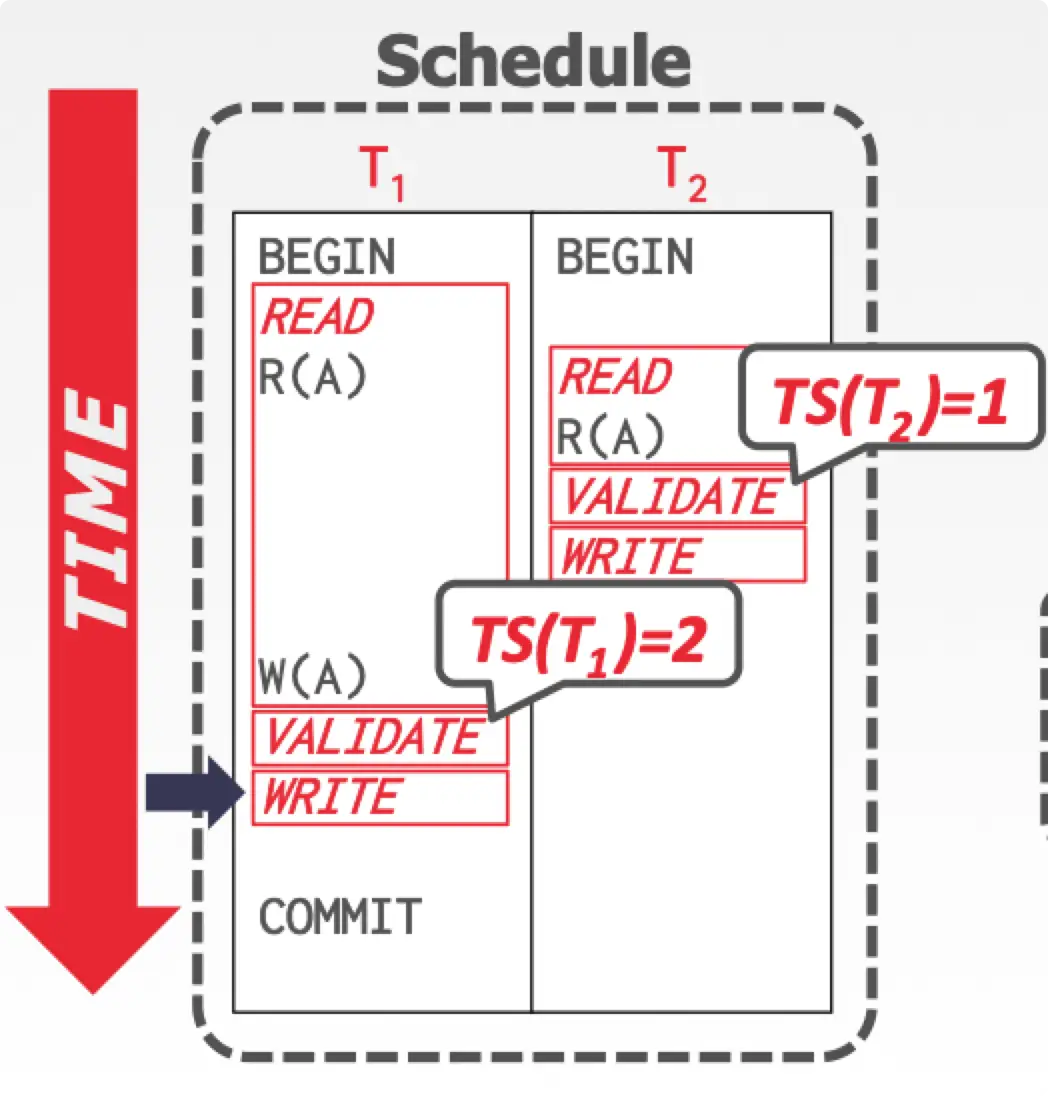
因为 为 read-only 事务,没有 write phase 阶段,不会更新 A 的 ,然后 能够正常通过 validation phase,最后执行 write phase 完成事务。
Snapshot Isolation
快照隔离是目前数据库采取的主流手段,其实你也能从上面 T/O 中看到快照隔离的影子,可以说其是基于上面一步一步发展过来。快照隔离的代表作就是 MVCC。
Multi-Version Concurrency Control(MVCC)
MVCC 的核心思想就是每一个事务拥有属于一份自己的快照,writers 不会阻塞 reader,reader 也不会阻塞 writer。
Read-only 事务可以直接根据时间戳读取快照而不需要获取锁。
同时因为你实现了保留多个版本,你可以很容易的读取过去多个版本的数据。
每一个事务包含两个时间戳,一个是 和 , 代表事务的开始时间, 代表事务的 commit 时间。每一个事务 commit 成功后,会保存一个属于它自己的版本,其 version 为当前事务的 。
当事务读取数据时,读到 version 最新的 item 且满足 。
在写入时,如果存在 , 两个事务并发执行,我们可以采取 first committer wins 或 first updater wins 两种规则。
我们定义 和 的并发情况如下:
或
First Committer Wins:
当 决定 commit 更新 item 时,检查 item 的 Version 是否存在 的情况,如果存在,说明 已经在 执行期间已经先 commit 了。判定 获胜, 执行回滚。
总的来说实现 commit,就算谁赢。
First Updater Wins:
当 更新一个 item 时,会申请其 write lock,
- 如果得到锁,先检查是否存在在 执行期间发生了更新(采用上面的规则),如果有,则 abort。否则直接更新即可。
- 如果得不到锁,且锁被 持有, 等待,直到 执行完毕后获取锁,存在两种情况:
- 如果 是 abort 的, 获得锁,执行检查(因为 item 可能在被 释放的瞬间,被其他事务拿去修改了,你需要再一次检查),如果成功执行更新操作。
- 如果 是 commit 的,那么 直接回滚(因为 在 期间修改了数据)。
总的来说就是谁先更新到 item,就算谁赢。
Snapshot Isolation Serializability Issues
快照隔离看起来很美好,但是其有一个严重问题,就是不保证 serializability。
考虑如下 schedule:
| read(A) | |
| read(B) | |
| read(A) | |
| read(B) | |
| A=B | |
| B=A | |
| write(A) | |
| write(B) |
按照快照隔离, 和 都能够成功 commit,且最后的值相当于 A 和 B 的互换。但是这样显然不符合 serializable schedule,因为按照 serial schedule 来执行,最后 A 和 B 的值是相等的。
究其根本原因是两个事务在最后写入的时候,分别写入的是两个不同的 item,使得快照隔离无法检测冲突,这种现象也叫做写倾斜(write skew)。写倾斜属于幻读的一种特殊情况。
你可以根据上面两个事务画一个 Waits-for graph,两个事务很明显存在一个环。
Serializable Snapshot Isolation(SSI)
为了解决快照隔离会存在 non-serializable schedule,PostgreSQL 提出 SSI。
之所以快照隔离存在写倾斜问题,是因为事务的 Waits-for graph 存在一个环(是读写冲突),而又因为修改的是不同 item 无法被检测出来。
所以 SSI 的核心思想就是追踪所有的读写冲突,如果发现存在环,abort 掉其中的一个。
具体可以看这篇文章:https://zhuanlan.zhihu.com/p/103553619
Lock-based 的并发控制不存在 write skew。
Phantom Problem
产生幻读最主要的原因是我们的并发控制程序无法控制将来出现的 item。我们只要管住在事务执行期间不让插入新数据,即可避免幻读。
Conflict serializability on reads and writes of individual items guarantees serializability only if the set of objects is fixed. 因为幻读会插入新数据,objects 不是 fixed 的了。
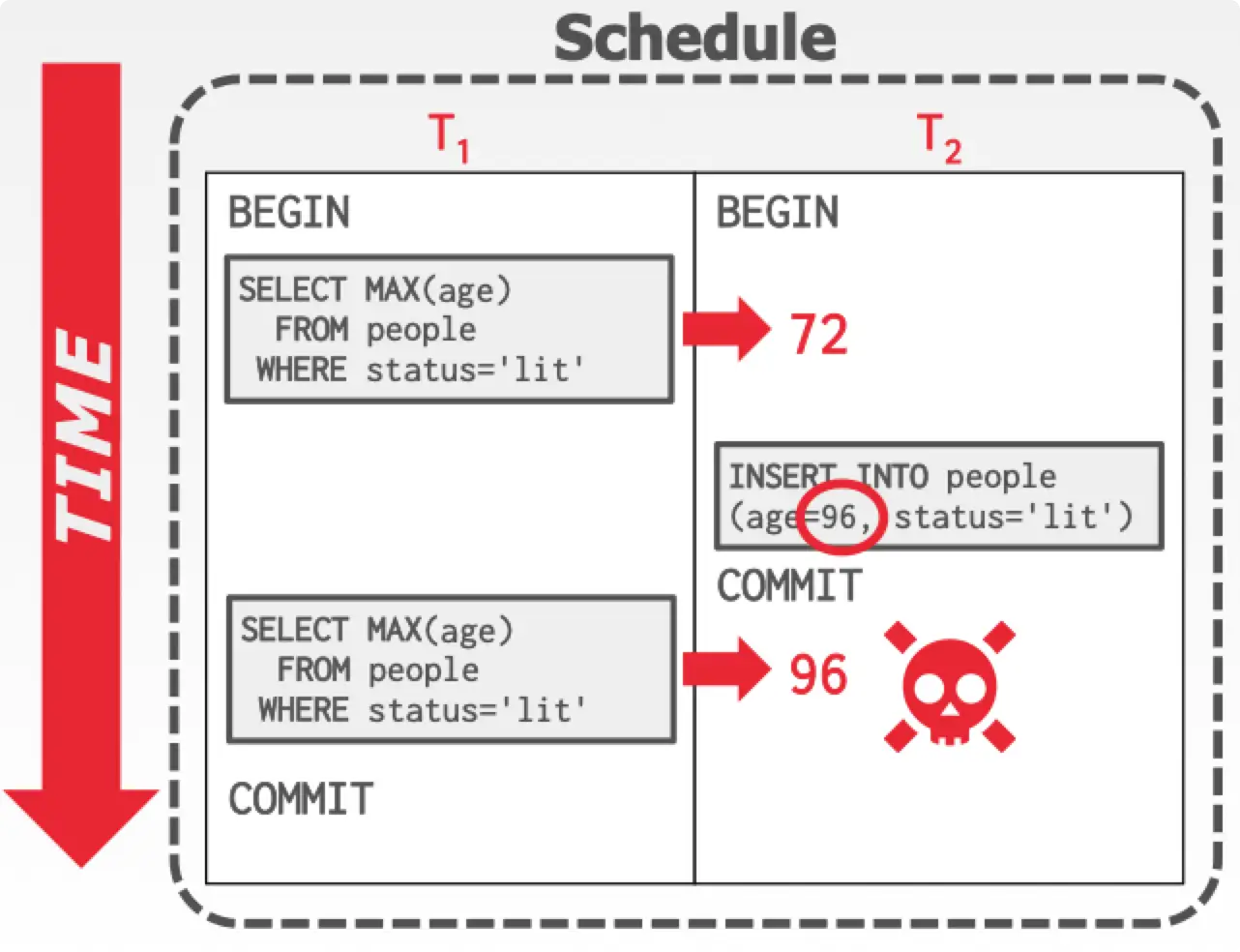
Solution
有如下三种解决办法:
Approach #1:Re-Execute Scans
在最后 commit 的时候,再重新执行一次 select 查询,检查数据是否有变化。如果变化,说明产生幻读。
Approach #2:Predicate Locking
对 predicate 条件上锁,比如下图锁住 WHERE status='lit' 这个 predicate,新数据尝试插入时,无法获得该锁,这样幻读就无法产生。
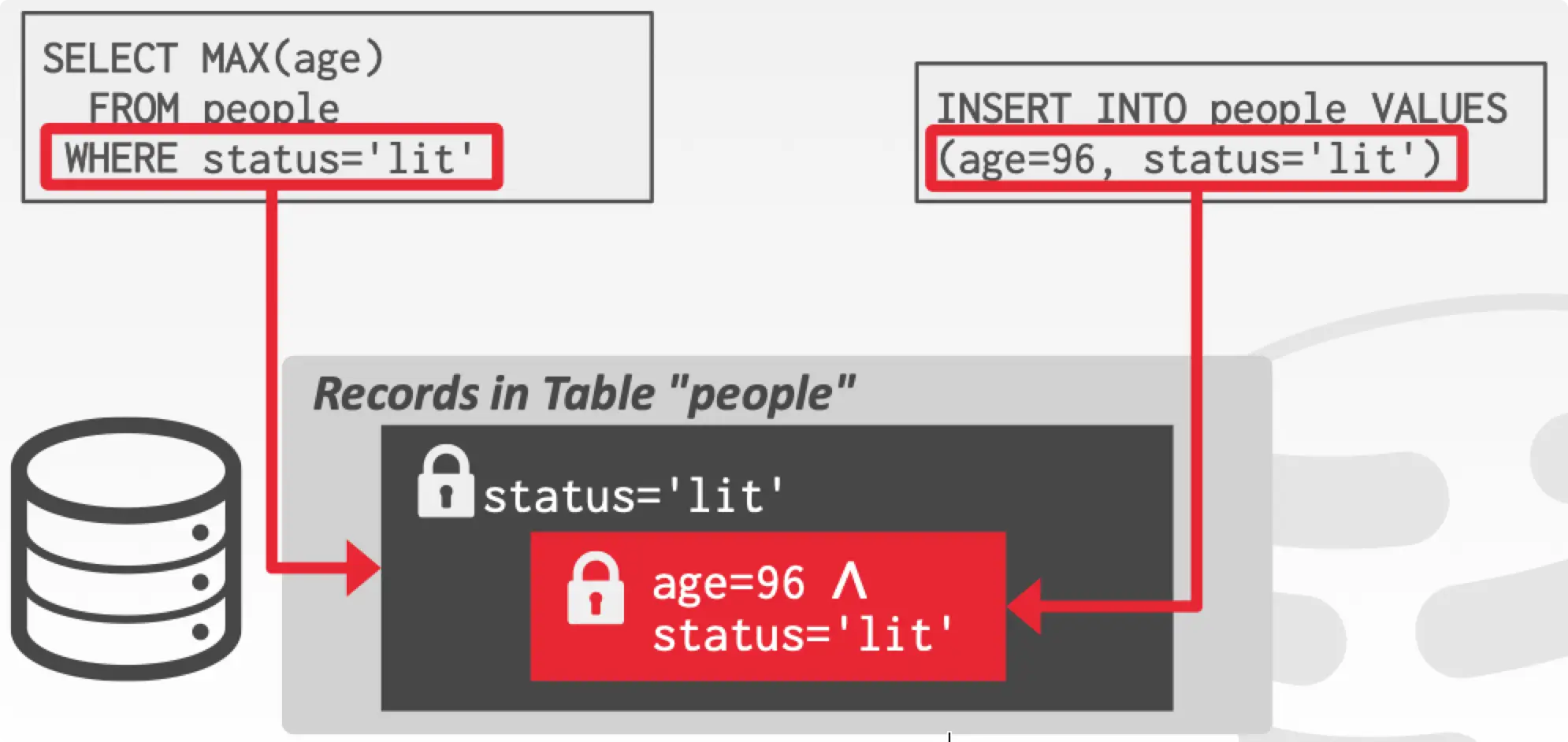
Approach #3:Index Locking
感觉和 predicate locking 差不多,可以锁住 B+ 树的索引节点。
MySQL 如何解决幻读?
原本想自己实操下幻读的,装了个 MySQL 8.0,结果发现死活复现不出来,插入操作会被阻塞掉,查了下,原来在 InnoDB 引擎下已经不可能产生幻读了。
上面这句话是之前的妇人之见,还是可以有幻读的,参考:https://github.com/ept/hermitage/blob/master/mysql.md#read-skew-g-single 。
MySQL 通过 Gap Locking(间隙锁)和 Next-Key 来解决幻读。
Gap Locking

如上图,在这个表中我们加入6个记录,0,5,10,15,20 和 25。会产生 7 个间隙,我们对这 7 个间隙加锁,使得别的事务无法插入数据,避免幻读的产生。
Next-Key
考虑如下 SQL 语句:SELECT * FROM demo WHERE id>30; ,MySQL 采用 Next-Key 方法,将 id>30 的范围全部锁住,确保别的事务无法插入,避免幻读。
Isolation Levels
Isolation levels 单指 ACID 中的 Isolation,更低的隔离级别意味着更高的并发。

| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现方法 |
|---|---|---|---|---|
| Serializable | 不可能 | 不可能 | 不可能 | 获得全部 Lock;加 index lock(避免幻读);加 strict 2PL |
| Repeatable read | 不可能 | 不可能 | 可能 | 和上面一样,不过无需 index lock,所以无法预防幻读 |
| Read committed | 不可能 | 可能 | 可能 | 和上面一样,不过读完就马上释放 S 锁,非 strict 2PL |
| Read uncommitted | 可能 | 可能 | 可能 | 和上面一样,不过不需要 S 锁 |
不同隔离级别产生的现象
简单总结下:
脏读:
- 事务 A 修改了数据 data,但是未提交。
- 同时事务 B 读取到了 data 的修改,称为脏读。
不可重复读:
- 在事务 A 的两次读 data 之间,事务 B 访问了数据 data,并修改了 data,并进行了提交。
- 如果事务 A 的前后两次读由于事务 B 的修改,导致的不一致称为不可重复读。
幻读:
- 与不可重复读的主要差别与幻读涉及的是插入操作,而不可重复读主要是更新操作。
- 事务 A 读某一范围数据并进行了修改,于此同时事务 B 在该范围新增了一行数据(Insert data)。
- 事务 A 可重复读,能读到原数据,但提交的时候会发现之前未查到的数据(Insert data)。
四种隔离级别例子
4 种隔离级别例子如下:
Serializable:可串行化
没啥好说的,不同事务不会并发同时执行。
Repeatable Read:可重复读
| Session A | Session B |
|---|---|
| begin; Select id from account; // get id(1), id(2) | |
| begin; Update account set id = 100 where id = 1; commit; | |
| Select id from account; // get id(1), id(2) Repeatable Read(可重复读) |
在 Repeatable read 中仍存在幻读,如下:
| Session A | Session B |
|---|---|
| begin; Select id from account; // get id(1), id(2) | |
| begin; Insert into account values(3, “Data”, 5000); commit; | |
| Select id from account; // get id(1), id(2) Repeatable Read(可重复读) | |
| Insert into account values(3, “Data”, 5000); // ERROR Duplicate entry ‘3’ for key ‘PRIMARY’ Phantom reads (幻读) |
Read Committed:读已提交
| Session A | Session B |
|---|---|
| begin; Select account from account where id = 1; // Will get 1000 | |
| begin; Update account set account = account + 500 where id = 1; commit; | |
| Select account from account where id = 1; // Will get 1500 committed read // Non-repeatable reads(不可重复读) |
Read Uncommitted:读未提交
| Session A | Session B |
|---|---|
| begin; Select account from account where id = 1 // Will get 1000 | |
| begin; Update account set account = account + 500 where id = 1 // Not commit here | |
| Select account from account where id = 1 // Will get 1500 dirty read (脏读) |
小结
至此,单机的并发控制差不多总结完了,其中大量篇幅在 ACID 中的 Isolation 中。总结如下几点:
- Lock-based 的通常是悲观事务模型,存在 deadlock 的可能,timestamp-based 的通常是乐观事务模型,基本不存在 deadlock,当然不是那么绝对。
- Lock 分为很多粒度,比如 database lock,table lock 再到行锁,属性锁等等。可以通过 Intention Lock 在一个被加锁节点的所有父节点添加信息,辅助其他事务快速判断是否会冲突。
- 数据库解决死锁采用死锁预防(遇到冲突,其中一个事务自己直接 abort,restart)或死锁检测与恢复(需要 Waits-for graph 判断是否存在环,然后选择一个事务杀死它)。
- 并发控制主要解决 ACID 中的 Isolation 问题,包含 Lock based,timestamp based 和 snapshot isolation 三种手段。MVCC 属于 snapshot isolation 的一种手段。
- MVCC 并不保证 serializable schedule,因为会产生幻读。
- Write skew(写倾斜)属于幻读的一种情况。
- MySQL 解决幻读的方法是引入锁(Gap Locking,Next-Key),PostgreSQL 解决幻读是采用 SSI。
- 越低的隔离级别性能越高。
好文推荐
记录一下自己在并发控制里面看到的好文章。


讨论一下
concurrency control的问题,wait-die情况下,方式1:老事务在
rid0的lock队列里,新事务想加入rid0的lock队列立马就abort掉比如以下加锁(√为加锁)顺序:
方式2:老事务在
rid0的lock队列里,新事务想加入rid0的lock队列,没有造成循环等待就加入,否则就abort掉环形等待条件,比如以下加锁顺序:
在你的方式(方式1)下,如果
txn0是正常加锁,那么不等txn0解锁,txn1就abort了(这里不符合常理,txn0是正常加锁,不是死锁,那么txn1就不该abort)很抱歉,估计回答不了你的问题,我有点忘了。。。。
然后也比较忙,没有时间重温这一块。
😅
我理解wait-die和would-wait只是一种死锁预防算法,没办法知道当前是否死锁,只是减少出现死锁的情况而已
确实不能知道是否产生死锁,但是他能打破死锁,应该不是
减少出现死锁的情况把。嗯我的表述有些问题,但我想楼主的意思是出现死锁才会使用到该算法的策略?楼主应该是觉得方式1中,Txn1等待老事务释放锁就好,不需要abort。但我在wait-die策略中主动abort的目的在于
预防老事务饿死,将等待释放锁的权力只交给老事务,就不会出现循环等待。