ChatGPT 牛逼,我准备下岗了
最近看一段 CSV 代码申请大量内存的问题,…
“This is the way”
“This is the way”

最近看一段 CSV 代码申请大量内存的问题,…
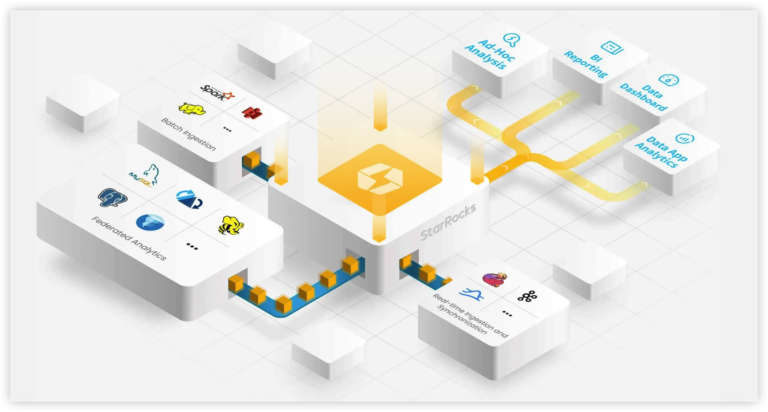
Chinese version: …
自从用了远程开发机,天天和命令行打交道…
本文于 2024 年 12 月 10 日再次更新,对…
文章随手写的,有需要的自己看看。 ES 相…
这篇文章已经 Deprecated 了,请大家看 ht…
这篇文章已经 Deprecated 了,请大家看 ht…
Bitmap Indexing 顾名思义,使用位图实现…
文章在 2024 年 11 月 3 日更新了下折腾日…
匆匆忙忙的春招告一段落了,自己最后也找…